Tuesday, April 16. 2013
Lange Zeit ist mir das schon auf der Zunge gelegen, aber Fefes Artikel zu Lizenzen hat endlich das Fass zum Überlaufen gebracht.
Um es mal direkt auszudrücken: ich hasse dieses mitschwingende Überlegenheitsgefühl, wenn FOSS-Leute die achso tolle GPL als bestes Geschenk an die Menschheit anpreisen und im selben Atemzug über andere Open-Source-Lizenzen herziehen. Nicht nur bei Fefe, in den letzten Jahren ist mir das nur zu oft untergekommen. Ich war so vor ca. 10 Jahren selbst so naiv, ähnlich zu agieren. Das Free-Software-Mitläufertum. Der (überspitzt gesagt) Gutmenschenlizenzterror gegen alle, die nicht mit der Einheitsmeinung konform gehen. Jaja, "Gutmensch" ist ein verbranntes Wort und so, aber GPL-Apologetik ist in meinen Augen in den meisten Fällen unglaublich moralinsauer.
Es gibt Gründe, andere Lizenzen als die GPL einzusetzen. Ich werde exemplarisch ein paar aufzählen.
Mein persönlicher Grund, eine andere Lizenz als die GPL einzusetzen (zugegeben, ich habe bis ca. 2006 auch unter der GPL veröffentlicht), ist, dass ich Komplexität hasse. Komplexität nicht nur in Software, sondern auch in ihrer Lizenzierung. Ich will die Lizenz, die ich verwende, vollständig lesen und verstehen können. Bei meiner favorisierten Lizenz, der MIT License, da geht das. Der gesamte Lizenztext besteht aus gerade mal 162 Wörtern (sagt wc), in relativ leicht verständlichem Englisch, das mal schnell überfliegt und man danach trotzdem noch gut erklären, was die wichtigen Punkte der Lizenz sind. Wer kann das von der GPL behaupten?
Und genau darin sehe ich einen entscheidenden Nachteil der GPL, egal in welcher Inkarnation: niemand (außer ein paar wenigen Spezialisten) versteht die GPL tatsächlich in ihrer Gesamtheit. Die GPL ist sprachlich auch in einem teilweise eher komplexen Legalese gehalten, und auch extrem lang. Und was erlaubt bzw. verbietet die GPL eigentlich? Tja, darüber scheiden sich die Geister. Zumindest, wenn man mit "Otto Normal-Entwickler" spricht. Die Gesamtheit der Mythen über die GPL ist unfassbar lang, dementsprechend viel "debunking" findet man etwa auf Google. Und woran liegt das letztendlich? Weil niemand die GPL liest und versteht! Niemand wendet sich der Primärliteratur zu, und quasi jeder kriegt seine Meinung aus Sekundärquellen, die die GPL interpretieren. Und gerade wenn man die Interpretationen von GPL-Apologeten wie Richard Stallman liest, merkt man, dass die GPL nur allzu schön dargestellt wird. Und ein "Herr Richter, bitte, RMS, die FSF und Eben Moglen haben aber gesagt, dass..." kann bei einer gerichtlichen Auseinandersetzung schon mal schön nach hinten losgehen.
Insgesamt halte ich das vollständige Verständnis von Lizenzen, die man selbst einsetzt, für einen Emanzipationsschritt, für eine Befreiung von den herrschenden Meinungen sogenannter Vordenker. Jeder Entwickler sollte sich ernsthaft zurücklehnen und fragen, "was will ich denn eigentlich mit der Lizenzierung meiner Softwarebezwecken?"
Ein weiterer Aspekt neben dem Verständnisargument ist meiner Meinung nach auch folgender: Software ist Infrastruktur für andere Software. Software kann (de-facto-)Standards prägen. Um diese Möglichkeit überhaupt zu eröffnen, ist eine weite Verfügbarkeit zweckmäßig, ja sogar notwendig. Warum mehrere Implementierungen von Kompressionsalgorithmen schaffen, wenn man eine einzige schaffen kann? Warum mehrere proprietäre, unvollständige und buggy Implementierungen eines HTTP-Clients, wenn man libcurl einsetzen kann? Die zlib steht unter der zlib-Lizenz. bzip2 steht unter einer BSD-artigen Lizenz. libcurl steht unter der MIT License. Ich nenne das als Beispiele für essentielle Infrastruktur. Würden diese (und andere) Libraries unter der GPL stehen, dann hätten wir mit Sicherheit etliche Interoperabilitätsprobleme und proprietäre buggy Implementierungen mehr, evtl. noch mit einer Prise Sicherheitslücken oben drauf. Eine Vielfalt an Open-Source-Lizenzen kann auch eine Verbesserung von code reuse bedeuten.
Ironisch ist ja, dass die FSF dieses Problem erkannt hat, und die LGPL erschaffen hat, gegen die man linken kann, ohne dass die dagegen gelinkte Software ebenso unter die Lizenzbedingungen der Library fällt. Die LGPL ist noch komplexer als die GPL. Ich erinnere mich an einen Chaos Communication Congress vor etlichen Jahren, wo Fefe in einem Q&A anführte, dass die meisten Entwickler die Details der LGPL gar nicht kennen. ACH! Ich hab ja gerade selber reingeschaut, und finde etwa die Sektion 3 der LGPLv3 durchaus spannend. Warum ist das bei Templates eigentlich auf 10 oder weniger Zeilen beschränkt? Ich denke da nur an template-lastiges C++. Und trotz der LGPL ist nur wenig (L)GPL-lizenzierte Software tatsächlich Infrastruktur und "systemrelevant", mit Ausnahmen wie glibc, libgcc, libstdc++ und ähnlichem Kram. Schaut euch das selber mal auf euren Systemen an. Noch weniger im Web. Wer relevant sein will, öffnet sich auch der Möglichkeit, dass seine Software auch in proprietären Projekten verwendet werden kann.
Aber gut. Was ich allerdings wirklich unredlich von Fefe finde, ist seine Annahme, BSD-lizenzierter Code wäre geklaut. Klauen, das ist fast so schlimm wie Raubkopien!!!1! Und er moniert, dass Leute, die sowas tun, nicht mal den ursprünglichen Autoren bescheid geben müssen. Natürlich nicht. Ist ja auch völlig konform zur Lizenz. Dass der Autor der Software das möglicherweise in voller Absicht getan hat, kommt ihm gar nicht in den Sinn. Ich kann aber für mich sprechen, und die von mir unter der MIT License veröffentlichte Software ist das mit voller Absicht. ICH BIN DER AUTOR, UND ICH WILL DAS GENAU SO HABEN!!! NIEMAND "KLAUT" DA WAS!!!
Das bringt mich zum nächsten Grund, warum jemand Software unter einer anderen Lizenz veröffentlicht: weil es niemandem schadet. Für mich selbst betrachtet: welchen Nutzen habe ich, wenn ich meine Software unter die GPL stelle? Damit ich irgendjemandem mal in Zukunft verbieten könnte, meine Software in seine zu integrieren? Wenig realistisch, und dann noch dazu viel zu konfrontativ. Und: was bringt's? Niemand wird mir wegen solcher Einschränkungen eine Lizenz abkaufen wollen oder mich anstellen oder ähnliches, nein, man sucht weiter nach einer offeneren Alternative.
Seit Anfang des Monats hab ich ja einen neuen Job. Bei meinem neuen Arbeitgeber ist es Policy, dass Software, die als Open Source veröffentlicht wird, unter der 3-clause BSD license stehen soll. Und warum? Weil es niemandem schadet. Konkret schadet es meinem Arbeitgeber nicht, Dinge, die dort entwickelt werden, offenzulegen, und zwar in einer Form, die es anderen ermöglicht, diese Software zu nehmen und damit ihr ganz eigenes, proprietäres Softwareteil zu bauen, auf dem sie dann ihr Startup fußen lassen und Arbeitsplätze und persönliches Vermögen schaffen. Und damit man nicht falsch versteht, ich sehe Harald Weltes Bemühungen, GPL-Verletzungen zu verfolgen, unter dem selben Licht, nämlich dass Harald Welte schon der Meinung ist, dass es ein Schaden ist, wenn seine Software ohne Einhaltung der Lizenzbedingungen verbreitet wird, und er verfolgt das auch entsprechend. Was Fefe und mich an dem Punkt allerdings unterscheidet, ist, dass ich beide Sichtweisen für durchaus legitim betrachte, während Fefe den Einsatz aller Lizenzen außer der GPL in ihren Ausprägungen delegitimiert.
Letztlich führt dieser GPL-Radikalismus mit AGPL etc. ja nicht dazu, dass mehr Software unter der GPL veröffentlicht wird, sondern dass mehr Entwickler darauf schauen, einen weiten Bogen um die GPL zu machen, um ja nicht "infiziert" zu werden (das finde ich übrigens auch spannend, von GPL-Apologeten wird ja immer geleugnet, die GPL hätte einen viralen Charakter, während Fefe das offen ausspricht).
Tuesday, December 18. 2012
Recently, I've been programming more and more in the Go programming language. Since my editor of choice has been vim for the last 10 years or so, I use vim to edit my Go code, as well. Of course, when I'm programming, I want my editor to support me in useful ways without standing in my way. So I took a look how I could improve my vim configuration to do exactly that.
The first stop is in the Go source tree itself. It provides vim plugins for syntax highlighting, indentation and an integration with godoc. This is a start, but we can go a lot further.
If you want auto-completion for functions, methods, constants, etc., then gocode is for you. After installation (I recommend installation via pathogen), you can use auto-completion from vim by pressing Ctrl-X Ctrl-O.
But with auto-completion, we can go even further: with snipmate, you have a number of things like if, switch, for loops that you can auto-complete by e.g. typing "if" and pressing the tab key. You can then continue pressing tab to fill out the remaining parts.
Another feature that I wanted to have as well was an automatic syntax check. For this task, you can use syntastic. But better configure it to passive mode and activate the active mode only for Go, otherwise other filetypes are affected as well. syntastic will call gofmt -l when saving a Go source file and mark any syntax errors it finds. This is neat to immediately find minor syntax errors, and thanks to Go's fast parsing, it's a quick operation.
Last but not least, I also wanted to have some features that aren't specific to Go: first, a file tree (but only if I open vim with no specific file), and second, an integration with ack to search through my source files efficiently and directly from vim. As a file tree, I found nerdtree to be quite usable, and as ack integration, I used this simple configuration snippet:
function! Ack(args)
let grepprg_back=&grepprg
set grepprg=ack\ -H\ --nocolor\ --nogroup
execute "silent! grep " . a:args
botright copen
let &grepprg=grepprg_back
endfunction
command! -nargs=* -complete=file Ack call Ack()
For my complete vim configuration, just take a look at it in my dotfiles repository. Enjoy!
Tuesday, May 8. 2012
Recently, I had quite a lot of free time to do stuff on my own. I'm currently unfit for work, and have been for over 2 months now, while I'm being treated for depression (don't worry, it's getting better).
To get myself going and get back on my feet, I started taking playing with technologies that I had recently read about, and built some simple things with them. As usual, I publish my works as open source. meta.krzz.de is one of these things. It's a meta URL shortener that will submit your URL shortening request to a number of URL shorteners in parallel, in display you the shortened URLs as they are received. See here for the source.
The interesting thing about this project is that it's essentially my first project involving AJAXy things and a shiny user interface (I used Bootstrap for the UI). I never really liked JavaScript, due to quite a few awkward language properties. Instead, I tried out Dart, a new language by Google that is meant as a replacement for JavaScript and currently provides a compiler to translate Dart code to JavaScript.
Dart is rather conventional. It obviously reminds one of Java, due to a very similar syntax. With its class system, it also provides compile-time checks that rule out a lot of errors beforehand. In addition, the generated code is meant to be quite portable, i.e. it should work with all/most modern browsers. Even though the documentation is terrible, I still found my ways a lot quicker than with my previous attempts with JavaScript. I got code running pretty quickly, had some first prototype, and from there on, it went quite fast. So Dart got me kind of hooked. Client-side web programming suddenly seemed easy.
So the next thing that I tried out was building a location hash router. The location hash is the part after the # sign that you may sometimes see in URLs. In recent times, it got more popular to keep the state of so-called single-page apps, web applications where all communication to the server is done using AJAX and the page is modified not by reloading but by modifying the DOM tree instead. You can find the source for hashroute.dart here.
The idea behind it is that you define a number of path patterns, Sinatra-style, e.g. /foo/:id, and callbacks that will be called whenever the location hash is set to a value that matches the pattern. When you look at the source, this is surprisingly simple and easy to understand.
And so I tried out another thing in Dart. David Tanzer recently told me about his idea of writing a blackboard application, where one user can draw something (his idea was using a tablet computer) and others can watch this in real time in their browser. After having a rough idea how I could implement that, I started a prototype with Dart on the client-side and Go on the server-side. You can find the source for the prototype here. The drawing is done on a HTML5 <canvas>. The Dart client not only allows the drawing, but records the coordinates for every stroke, and sends them to the server using WebSockets. The server takes these coordinates and forwards them to all listening clients, again via WebSockets. The "slave" is equally simple: it opens a WebSocket to the Go server and draws all incoming strokes according to the submitted coordinates. Currently, there is no authentication at all, and it's only a very early prototype, but this is not only a piece of code that (again surprisingly) simple, but also an idea that could evolve into a useful tool.
In total, I'm very satisfied with how straightforward Dart makes it to write client-side web applications. I've been pretty much a n00b when it came to the client side of the web, but with Dart, it feels accessible for me for the first time.
Sunday, October 9. 2011
A bit more than a year ago, I started baconbird, my first attempt at a Twitter client that fits my requirements. I worked on it for some time, and it reached a level where it was usable, and where I was pretty happy with it. But due to a few poor choices, chances for further development diminished, and I basically halted the project, and only used the software. And after using it for a few months, more and more principal defects, practically unfixable, came up. Just too much began to suck, so earlier this week, I decided to throw baconbird away and reboot the whole project.
But first things first: my first poor choice was using Perl. Sure, Perl provided me with all the tools to come to meaningful results really quickly, through the vast amount of ready-to-use modules in the CPAN archive. And that's what's really great about it. What's not so great about Perl are the ideas of concurrency. You basically have to resort to event-based, async-I/O programming, which is not only painful by itself, but also extremely painful to integrate with my widget set of choice, STFL. And threads in Perl... don't do it, that's what everyone says. That meant that I couldn't do any of the Twitter communication asynchronously in the background, but had to do it in my primary thread of execution, essentially make it part of the subsequent calls of the input loop, if I wanted to retain sanity and a certain level of productivity. And that made baconbird really slow to use, and when Twitter's API was offline, baconbird practically hung. That made baconbird just a PITA to use, and I had to change something about it.
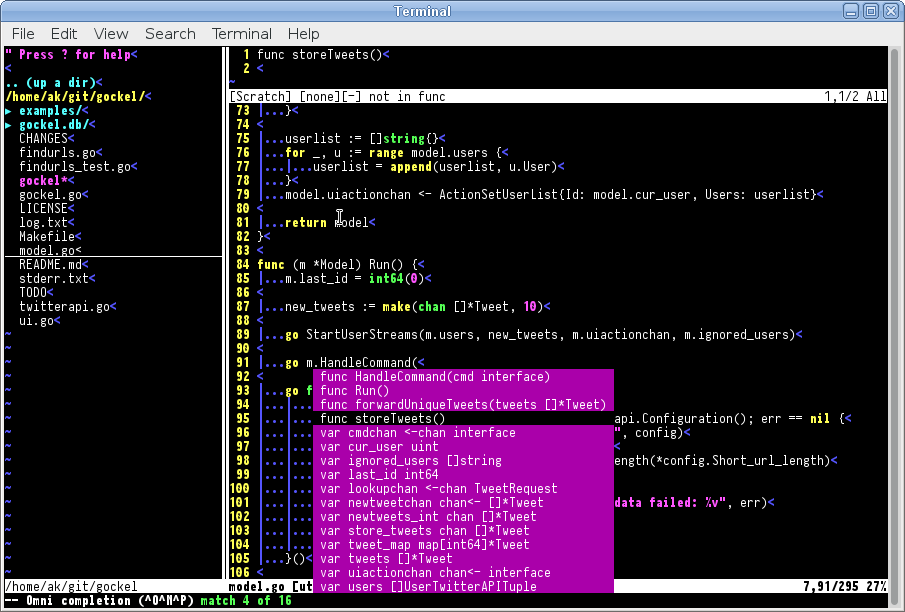
Also, in the last few months, I played more and more with Go, a programming language developed by several people at Google, many of which were formerly involved in projects like Unix or Plan 9. I became more fluent in it, and I really liked the concepts of Go about concurrency, parallelism and IPC. Also, I played with Go's foreign function interface, cgo, and built a wrapper around STFL so that it could be used with Go. So, essentially, Go would provide me with a few language features that I totally missed in Perl, while it wouldn't provide me with other niceties, like a CPAN-like repository. But finally, I decided to just bite the bullet, at least build upon an existing OAuth implementation for Go, and started my second incarnation of an STFL-based Twitter client, this time written in Go. And, after some initial prototyping that started last Thursday, I put more work into it this Saturday and Sunday, and today I reached the point where I had some code to show that wasn't completely ugly, had some structure and the basic outlines of an architecture, and that obviously didn't suffer from all the negative things that I hated about baconbird.
The overall structure is simple: three goroutines are started, one for the model (which does all the interaction with the Twitter API), one for the controller (which, now that I think about it, may be obsolete, because it doesn't do that much except for receiving new tweets and sending them to the UI), and one for the user interface (which does all the non-interactive redrawing and UI fiddling). Reading the user input is done in the main execution thread of the program, but no parsing is done and all input is given directly to the user interface goroutine. As already suggested, these three goroutines communicate using channels. When the model receives new tweets, it sends them to the controller, the controller puts them into a list of all tweets and then forwards them to the user interface, and the user interface inserts them into the list of tweets that are displayed to the user. And when a new tweet is sent, the text for it is read by the user interface, but is then sent to the model (again via a channel; i.e. the application won't block while the tweet is being transmitted to Twitter), and when sending the tweet is finished, the Twitter API returns the tweet object, which is then again handed over to the controller and the user interface (so that you can immediately see your own tweet in your home timeline as soon as it's reached Twitter). That's basically all the functionality that's there, but there's a lot more to come.
And before I forget it: the code is already out there. Visit gockel ("Gockel" means "rooster" in German, which is a type of bird [Twitter, bird, you know], and I chose it because the first two letters also give a hint about the programming language in which it is being developed), and read the source code, which I consider to be rather simple and easy to understand. A lot more will change, new features, everything will be better, and hopefully soon, gockel will be ready to achieve world domination. No, seriously: this reboot finally gives me the ability to (hopefully) implement the Twitter Streaming API with only minimal amounts of pain.
Tuesday, July 5. 2011
In the last few months, from time to time I experimented with the programming language Go, a new systems language released only in 2009 and developed by people like Ken Thompson, Rob Pike and Russ Cox at Google. While still staying relatively low-level, it adds a garbage collector, and simple object/interface system, and the mechanisms of goroutines and channels as means of concurrency and inter-process communication (or should I say inter-goroutine communication).
In the last few days, I found more time to experiment with Go, and finally fully got the hang of the object system, and I must say that I really like it, both for the simplicity and the expressiveness. Objects in Go feel so simple, so natural, and at the same time powerful, with very little syntactic overhead. So that's what I want to write about today.
Let's start with a simple example:
Here we created a new type Vehicle with one private member "speed", and a method Speed() that returns the current speed. Of course, a vehicle all by its own isn't very useful, so we define the minimal requirements for a vehicle that's actually usable:
Here we define an interface named Drivable that defines the required methods for an object to be drivable, in our case, it must be able to accelerate, brake and show the current speed. Based on this, we construct our first actually usable vehicle:
And voila, we have our first Car that is also Drivable. What did we exactly do here?
We created a new type Car that is a struct, and embedded the type Vehicle: instead of adding a named member, we added an unnamed member, only specified by the type. This embedding also makes all available methods for this type available to our new type, i.e. a method Speed() is now also available for our type Car.
In addition, we implemented two new methods, Accelerate() and Brake(), in order to match the interface Drivable. And last but not least, we implemented a function to create a new Car.
Now, let's create another type of Drivable vehicle, let's say a boat:
So far, so uninteresting. The implementation of the boat is basically the same as the car, so nothing new.
But now I want to go a step further and implement and amphibious vehicle that is both a car and a boat. Let's just do that:
But that doesn't quite work out, because when we try to compile it, we will see an error message like this:
Since we embedded both Car and Boat into Amphibian, the compiler can't decide which Accelerate() method it shall use, thus communicating it as ambiguous. Based on that, it also says that it can't create an object of type Amphibian as Drivable because it has no proper Accelerate() function. This is the classic problem of diamond inheritance that we need to resolve here, not only for Accelerate(), but also for Brake() and Speed(). In the case of the amphibious vehicle, we do this by returning the right speed depending on whether the vehicle is in the water or on land:
And of course, the object perfectly works as Drivable:
So, what I just showed you are the capabilities in what Go modestly calls embedding but that feels like multiple inheritance and is really simple at the same time.
For a more complete view on Go and its features, I recommend the official Go documentation, and especially " Effective Go", a document that introduces the most important Go features and shows how to write idiomatic Go code. The complete example source code can be found here.
Saturday, January 15. 2011
Through this tweet, I got aware of redo, a build system with an interesting approach. It's based on some ideas that djb wrote down on his website, but apparently never published any code. This blog posting even goes as far as claiming that redo could be the Git of build systems. It argues that Git replaced most other widespread open source VCS because it's simple and flexible, and redo will go the same way for the same reasons.
I'm a person who is usually open to new approaches regarding development/build infrastructure, and so I evaluated redo by converting the build system of newsbeuter to redo. I chose newsbeuter not only because it's my most successful project so far, but also because it is typical for how I structured projects and their build system in the last few years, and it's non-trivial: some .o files are packed into .a files, two different binaries are built that share a common library, .h files are created from other text files, and it's currently all done by a single, non-recursive Makefile. The hypothesis is that if I can use redo to build newsbeuter without any hassles or weird hacks or workarounds, then it's good enough for what I need.
The actual conversion took me about an hour, maybe a bit more. Documentation could answer all my questions, except for those things that I stumbled upon that I consider to be bugs (I will report them later, don't worry). It was really hassle-free and straightforward, and at no point I was ever confused because I hadn't fully digested a new but poorly explained concept yet. But I think that the claim of redo being the Git of build systems can't be held up.
And that is because of one major thing: redo tries to do things "right", and it does so by implementing one certain approach and one certain approach only: redo doesn't support non-recursive builds. If I want a rule to apply to e.g. .cpp files in the root directory and in the src subdirectory, I will have to duplicate this rule. Since redo rules are basically shell scripts, this can be easily deduplicated, but a problem arises when e.g. the command line to compile .cpp to .o files contains -I options to reference files in the local project directory. For the .cpp file in the root directory, such an option has to be "-Iinclude", while for a .cpp file in the src subdirectory, it has to be "-I../include". I don't see anything in redo's documentation that the author has thought of that situation in any way, he even explicitly states that "There is no non-recursive way to use redo."
And that's the fundamental difference to make (the make I use is GNU make, just to make that clear), where I as a developer can choose to use make either in a recursive or non-recursive fashion, whichever I prefer. redo really lacks flexibility here. I would probably be able to solve some of my issues by restructuring the source tree to work around these deficiencies, but why would I want to do that? Tools are supposed to work for me, and not the other way around, they should be flexible enough to be adaptable to my needs, and I shouldn't need to adapt my existing project to make it fit to what redo expects.
So, redo, from a conceptual point of view, has a really good and simple approach (very djb-y), and I'm sure it's an excellent tool for new projects, but for existing projects that already use make in a non-recursive fashion, it would a maintenance PITA. And that's why I conclude that redo in its current conceptual state will never be the Git of build systems. make is still more flexible, and even though it has its flaws, it's still good enough for most people, and also a de-facto standard.
Monday, January 10. 2011
In this posting (and also this one), Su-Shee pleads for a more vocal and active promotion/advocacy. While I know how nice it can be to use a piece of software that makes people envious, I just want a quiet, hype-free, pragmatic, down-to-earth knowledgable community, and I will explain why.
Some years ago, summer or fall 2002, if I recall correctly, there was this new object-oriented programming language that everybody was talking about, that was quite obscure but really cool because you could write compact, easy-to-read, object-oriented code, in a fashion not unlike Perl. That programming language was Ruby. Having had a background of Pascal, C, and some C++ and Perl, I was astonished by the expressiveness and flexibility of the language, without losing readability. I used Ruby for quite some time, worked on some silly open source project with it, I used it for scripting at work (until my then-boss prohibited the use of any programming language for which no other developer in-house had any knowledge), I wrote daemons that formed the glue between email and MMS systems, I even used it as exploratory prototyping language for stuff that I would later rewrite in C. And then came Rails.
Rails was hyped as the greatest invention since sliced bread, the be-all end-all of web development. As somebody who had previously only known CGI.pm and cgi.rb, this indeed looked intriguing. I had a closer look, bought a book, played with it, and found it quite OK. Until I wanted to do things differently than what the usual tutorials had in mind. Useful documentation about the greater context and overall concepts was sparse (be aware, this was pre-1.0 Rails, things may have changed a lot since then), and I felt constricted by too many things in Rails (this has most likely been addressed in later releases; I haven't bothered to look back since then, though). So many things that were advertised as awesome turned out to be nice, but not that impressive on closer inspection.
And this is exactly what I don't want to do, namely awakening false hope in people about awesome features of $SOFTWARE, and I think an overly optimistic presentation of a system's features can easily lead to exactly that. In fact, the only screencast that didn't disappoint on closer look was Google's launch of the Go programming language in 2009, but that only as a side note. Self assurance is nice at all, but in my experience, there's only a fine line between self assurance and misrepresentation.
Another aspect of the Rails hype was the complete turn-over of a great portion of the Ruby community. The usual community and support channels were flooded with people interested in Rails, Rails became synonymous with Ruby, the signal-noise ratio drastically became worse. Some people even tried to actively recruit me for open-source Rails projects because I "knew Ruby". I declined, because the web applications aren't my area of interest at all (even today, the only things I have to do with web is that I hack on stuff like Apache and PHP [the interpreter] for a living; still, no web development).
Yeah, the community turn-over. Soon, people with big egos and great self assurance surfaced, dubbing themselves rockstars or ninjas or similar. I always found these to be acts of total douchebaggery, because, in the end, they all only cooked with water, anyway (a notable exception was why the lucky stiff). These were the people with great self assurance and a total lack of self-criticism or reflection on one's own work. It's not the kind of people whose software I would want to use, because too often my experience was that some library, framework or tool was announced with big words, which then practically always turned out not to be great at all, sometimes even barely usable or totally buggy.
And that brings me back to the original topic of Perl. Exactly the things that I learned to despise about the culture revolving around Ruby and Rails are something that I haven't experienced in the Perl community at all so far. Libraries, framework, documentation and people had more time to mature, probably, while still being down-to-earth. I can expect good documentation, functioning software, friendly people and most importantly accurate words in announcements and discussions.
Through my current employment, I found the way back to Perl, using it at work and also for some personal stuff. I recently even started a new open source project where I productively use Moose for the first time. My code is probably not very expressive and may seem weird (I know, TIMTOWTDI), but at least I feel comfortable writing it. I'm fine with most things surrounding Perl, its eco-system and its communities, and so I don't want to see any kind of interruption and turn-over like I saw it with Ruby.
Tuesday, November 23. 2010
Na, wer hätte das gedacht? (D)DoS-Angriffe auf Apache nach der Art von Slowloris funktionieren auch mit HTTP POST. Wong Onn Chee und Tom Brennan zeigen in dieser Präsentation, dass es genügt, nur genügend Verbindungen zu einem Webserver aufzumachen, und dann POST-Requests zu beginnen und die nicht fertig werden zu lassen (indem man nur langsam die Daten reintröpfeln lässt), um einen Apache lahm zu legen. Bei Slowloris ging das ja auch noch mit HTTP GET und einem unfertigen Request dadurch, dass sehr langsam immer neue HTTP-Header gesendet wurden, ohne den Request wirklich abzuschließen. Und jetzt dasselbe in grün.
Ehrlich gesagt wundert es mich aber nicht, dass sich bei Apache dieses Problem mehrfach manifestiert. Schon im Zuge von Slowloris habe ich mich mit der Thematik beschäftigt, und basierend auf beruflich gewonnenen Erkenntnissen den Apache-Entwicklern einen Patch zukommen lassen, der im wesentlichen ignoriert wurde. In einem Lightning Talk auf dem 26C3 habe ich auch nochmal vor der Problematik gewarnt.
Das letztendliche Problem ist jedoch die kaputte Architektur von Apache, dessen sind sich auch die Entwickler bewusst, nur keiner will es ganz so offen zugeben. Eine Lösung von Apache-Seite gäbe es durchaus, und zwar das event MPM, an dem allerdings, soweit ich das verfolge, im wesentlichen keine Entwicklungsarbeit geschieht. Die konsequente Lösung ist, Apache einfach wegzuwerfen (ich bin etwa auf lighttpd gewechselt), wer aus historischen Gründen kurz- und mittelfristig nicht von Apache wegkann, dem kann ich nur mein Mitleid aussprechen.
Tuesday, October 5. 2010
Less than two weeks ago, I announced project "bacon bird". And today is the day where I can be proud to announce to first release of baconbird, my new twitter client for text terminals.
Baconbird, much like my previous successful project newsbeuter (an RSS/Atom RSS feedreader for those who haven't heard about it yet), targets people who tend to work on text terminals (using mutt, irssi, slrn, vim, etc. is a strong indicator for that), uses the fabulous STFL as its user interface library, and was created to scratch an itch. My itch in this case was Twitter's switch from basic authentication to OAuth, which had the negative side effect that it rendered all (authenticated) RSS feeds practically unusable, so I was stuck to using the web interface of Twitter, which I wasn't too happy about. Also, other Twitter clients were either slow, had weird user interfaces, or were simply CPU and memory hogs. And then there was the infamous Twitter XSS worm that affected quite a few people. All these things together brought me to the conclusion that I had to change something about that.
At first, I started hacking on another client, but soon I found out that the purely ncurses-based UI is virtually unmaintainable, and so I decided to do it right instead and write my very own thing. And that's how baconbird was born. The code itself is about 850 SLOCs of Perl code, the user interface is based on STFL, the Twitter backend uses Net::Twitter, and all the OO glue code in between uses the Moose object system. All in all it took me less than 2 weeks of my free time to develop the first version of it.
So, what features does baconbird offer? Not too much, so far, but enough for a start and to show it off. Of course, you can view the time line (i.e. all the tweets of you and the people you follow), your mentions, your direct messages, and searches. It reloads continuously, and takes care about the current rate limit as imposed by Twitter. You can post tweets, reply to tweets (it even tracks the status ID, i.e. in the web interface you can see proper "in reply to" links), retweet, send direct messages, reply to direct messages, and when writing tweets, you can even have your URLs shortened (I implemented integration with is.gd).
My personal favorite is the search feature, though, I can search for a certain word or hashtag, and I get a nifty live stream of the latest tweets on that. I can even switch to my timeline and switch back, and the live stream keeps on loading as soon as its view is active, until I switch to another view or start another search.
Baconbird is far from complete, though. I still need to implement subscription management, and everything else the Twitter API has to offer (as long as its applicable from a terminal application). I'm also glad to implement your feature requests. And last, but not least, if you like baconbird and to support its further development, I'd be happy about flattring it. You can also flattr this article, of course (</shameless-plug>).
Thursday, July 22. 2010
Introduction
In the beginning, there was char. It could hold an ASCII character and then some, and that was good enough for everybody. But later, the need for internationalization (i18n) and localization (l10n) came up, and char wasn't enough anymore to store all fancy characters. Thus, multi-byte character encodings were conceived, where two or more chars represented a single character. Additionally, a vast set of incompatible character sets and encodings had been established, most of them incompatible to each other. Thus, a solution had to be found to unify this mess, and the solution was wchar_t, a data type big enough to hold any character (or so it was thought).
Multi-byte and wide-character strings
To connect the harsh reality of weird multi-byte character encodings and the ideal world of abstract representations of characters, a number of interfaces to convert between these two was developed. The most simple ones are mbtowc() (to convert a multi-byte character to a wchar_t) and wctomb() (to convert a wchar_t to a multi-byte character). The multi-byte character encoding is assumed to be the current locale's one.
But even those two functions bear a huge problem: they are not thread-safe. The Single Unix Specification version 3 mentions this for wctomb, but not for mbtowc, while glibc documentation mentions this for both. The solution? Use the equivalent thread-safe functions mbrtowc and wcrtomb. Both of these functions keep their state in a mbstate_t variable provided by the caller. In practice, most functions related to the conversion of multi-byte strings to wide-character strings and vice versa are available in two versions: one that is simpler (one function argument less), but not thread-safe or reentrant, and one that requires a bit more work for a programmer (i.e. declare mbstate_t variable, initialize it and use the functions that use this variable) but is thread-safe.
Coping with different character sets
To convert different character sets/encoding between each other, Unix provides another API, named iconv(). It provides the user with the ability to convert text from any character set/encoding to any other character set/encoding. But this approach has a terrible disadvantage: in order to convert text of any encoding to multi-byte strings, the only standard way that Unix provides is to use iconv() to convert the text to the current locale's character set and then convert this to a wide-character string.
Assume we have a string encoded in Shift_JIS, a common character encoding for the Japanese language, and ISO-8859-1 (Latin 1) as the current locale's character set: we'd first need to convert the Shift_JIS text to ISO-8859-1, a step that is most likely lossy (unless only the ASCII-compatible part of Shift_JIS is used), and only then we can use to mb*towc* functions to convert it to a wide-character string. So, as we can see, there is no standard solution for this problem.
How is this solved in practice? In glibc (and GNU libiconv), the iconv() implementation allows the use of a pseudo character encoding named "WCHAR_T" that represents wide-character strings of the local platform. But this solution is messy, as the programmer who uses iconv() has to manually cast char * to wchar_t * and vice versa. The problem with this solution is that support for the WCHAR_T encoding is not guaranteed by any standard, and is totally implementation-specific. For example, while it is available on Linux/glibc, FreeBSD and Mac OS X, it is not available on NetBSD, and thus not an option for truly portable programming.
Mac OS X (besides providing iconv()) follows a different approach: in addition to the functions that by default always use the current locale's character encoding, a set of functions to work with any other locale is provided, all to be found under the umbrella of the xlocale.h header. The problem with this solution is that it's not portable, either, and practically only available on Mac OS X.
Alternatives
Plan 9 was the first operating system that adapted UTF-8 as its only character encoding. In fact, UTF-8 was conceived by two principal Plan 9 developers, Rob Pike and Ken Thompson, in an effort to make Plan 9 Unicode-compatible while retaining full compatibility to ASCII. Plan 9's API to cope with UTF-8 and Unicode is now available as libutf. While it doesn't solve the character encoding conversion issue described above, and assumes everything to be UTF-8, it provides a clean and minimalistic interface to handle Unicode text. Unfortunately, due to the decision to represent a Rune (i.e. a Unicode character) as unsigned short (16 bit on most platforms), libutf is restricted to handling Unicode characters of the Unicode Basic Multilingual Plane (BMP) only.
Another alternative is ICU by IBM, a seemingly grand unified solution for all topics related to i18n, l10n and m17n. AFAIK, it solves all of the issues mentioned above, but on the other side, is perceived as a big, bloated mess. And while its developers aim for great portability, it is non-standard and has to be integrated manually on the respective target platform(s).
Monday, July 12. 2010
OpenBSD ist - wie dem einen oder anderen Leser sicherlich bekannt sein dürfte - ein von NetBSD abgeleitetes Unix-artiges Betriebssystem, das seinen Fokus auf Sicherheit legt. Als Entwickler und Maintainer des mittlerweile halbwegs populären Open-Source-Projekts newsbeuter sehe ich es nicht nur als meine Aufgabe, neue Features zu entwickeln und bestehende Bugs zu fixen, sondern auch einen gewissen Aufwand darin zu stecken, die Software für ein möglichst großes Publikum auch tatsächlich praktisch zugänglich zu machen. Diese Aufgabe hat verschiedene Grundrichtungen. Das ist etwa die einfache Verfügbarkeit für Enduser (da habe ich beispielsweise vor kurzem erst eine Liste von Distributionen, die mit fertigen Paketen kommen, zusammengestellt), eine möglichst durchgängige Internationalisierung und Lokalisierung (so ist newsbeuter in mittlerweile 14 verschiedenen Sprachen verfügbar), oder aber auch, die Kompatibilität zu anderen Systemen als nur die populären Linux-Distributionen zu testen und zu gewährleisten. Letzteres hat dazu geführt, dass newsbeuter unter Linux, FreeBSD und Mac OS X läuft.
Vergangenes Wochenende habe ich mich daran gemacht, die Kompatibilität auch zu weiteren Systemen zu testen. Auf meinem Plan standen konkret NetBSD und OpenBSD. Der Zustand von NetBSD ist kurz geschildert der, dass die Citrus-Implementierung von iconv() in der Art und Weise nicht kompatibel ist, als dass es das spezielle Encoding "WCHAR_T", das von der STFL verwendet wird, nicht unterstützt. Das ist nicht schön, aber verkraftbar, da einerseits die von iconv unterstützten Encodings/Zeichensätze systemspezifisch sind, andererseits man da sicherlich auch (achtung, ungetestet!) die GNU libiconv einsetzen könnte.
Bei OpenBSD bietet sich hier ein völlig anderes Bild: hier scheiterte mein Versuchen, die STFL zu übersetzen, schon daran, dass OpenBSD über keine Implementierung von swprintf verfügt. Etwas verdutzt hab ich dann begonnen, weiterzurecherchieren, weil ich eigentlich der Meinung war, dass OpenBSD eigentlich schon mal die Arbeit des Citrus-Projekts importiert hatte, und bin schon nach kurzem über die nahezu talibanesken Ausführungen eines Herrn uriel, der einen Fanatismus dabei zeigt, auf den Unix-Standardweg für Internationalisierung (nämlich wchar_t + Funktionen darauf) zu verzichten und stattdessen UTF-8 als den Einzig Wahren Weg(TM) anzupreisen. Schließlich habe ich mich rangemacht, und geschaut, welche Funktionen aus wchar.h in NetBSD (die Citrus integriert haben), jedoch nicht in OpenBSD zu finden sind, und bin auf folgendes Ergebnis gestoßen. Dadurch, dass das nicht irgendwelche Pipifax-Funktionen sind, sondern da auch ein konkreter Standard bzw. hinreichend verbreitete Implementierungen dahinterstehen, ist die Liste nach Standards sortiert:
Single Unix Specification, Version 2- fwprintf
- fwscanf
- swprintf
- swscanf
- vfwprintf
- vswprintf
- vwprintf
- wprintf (wird aber in der Manpage von wcstok(3) erwähnt...)
- wscanf
Single Unix Specification, Version 3
Proprietär, aber in NetBSD und glibc zu finden- wcsdup
- wcsncasecmp
- wcscasecmp
Man beachte, dass die allermeisten Funktionen schon in SuSv2 spezifiziert sind und es als solche auch in C99 reingeschafft haben.
Tja, und da war es dann aus bei mir mit der guten Laune. Ist es tatsächlich zuviel verlangt von einem doch vergleichsweise populären Betriebssystem (gemessen an der Open-Source-Community, nicht der Gesamtheit aller Computeruser weltweit), etablierte Standards, die thematisch eigentlich genau in die Projektzielsetzung von OpenBSD fallen, umzusetzen, oder ist OpenBSD neuerdings dazu übergegangen, ein möglichst kastriertes System, das entfernt noch irgendwie an Unix erinnert, zu entwickeln? Es ist ja nicht so, dass die Komplexität der oben genannte Funktionen besonders groß wäre, immerhin gibt es davon ja fertige Implementierungen, die sogar in einer für OpenBSD akzeptablen Lizenz vorliegen (nämlich die Entwicklungen des Citrus-Projekts).
Unter solchen Voraussetzungen, dass nicht einmal 13 Jahre alte Standards aus dem C- und Unix-Umfeld umgesetzt werden, kann ich auf jeden Fall OpenBSD nicht mehr als ernstzunehmendes Unix-artiges Betriebssystem betrachten. Ich zeige kein Verständnis für Extrawürste und bewusst weggelassene Funktionalität. Solange nicht zumindest swprintf() in OpenBSD existiert, ist newsbeuter-Support für OpenBSD gestorben, explizit auch so dokumentiert, und ich kann nur jedem, der ernsthafte Open-Source-Entwicklung betreiben will, von einer angestrebten Kompatibilität mit OpenBSD abraten, weil dafür im Vergleich zu anderen System riesige Kompromisse eingegangen werden müssten.
Saturday, May 8. 2010
In letzter Zeit, vor allem nach Anschaffung eines eigenen Filmscanners, habe ich wieder angefangen, Schwarz-Weiß-Film selbst zu entwickeln. Da liest man immer wieder nach, was denn andere so schreiben über das Entwickeln von Film, und jedes Mal, wenn ich ein neues, anderes Tutorial finde, schlage ich die Hände über dem Kopf zusammen. Egal, als wie einfach und "für Einsteiger" so Beschreibungen bezeichnet werden, es findet sich immer wieder unnötiger Mist da drinnen, der insbesondere für Einsteiger und Anfänger viel zu verwirrend ist oder nur dazu dienen soll, den Verkauf von unnötigem Scheiß zumindest ein bisschen anzukurbeln. Meine Beobachtungen waren die Motivation, diesen Text mit meinen Gedanken und Tipps zum diesem Thema zusammenzuschreiben, basierend auf meinen Erfahrungen. Ich behaupte nicht, von der Materie was zu verstehen, aber immerhin beherrsche ich es gut genug, um meine eigenen Filme selbst zu entwickeln. Achja: durch den ganzen Text zieht sich eine "FUCK THAT SHIT!"-Einstellung, auf Genauigkeit und Dogmen wird geschissen.
Der Anfang
Also, man hat also einen Schwarz-Weiß-Film belichtet (ich kann hier nur von 120er-Rollfilm sprechen, 135er interessiert mich eher wenig). Man will den Film entwickeln, früher hätte man auch noch Abzüge davon gemacht, heutzutage bietet es sich eher eine Digitalisierung an, letztendlich will man die Bilder ja sowieso im Computer haben.
Die Entwicklerdose
Zum Entwickeln benötigt man zuerst ein lichtdichtes Gefäß, eine Entwicklerdose, bei der man den Film in eine Spule einwickeln kann. So Entwicklerdosen gibt's um EUR 20 bis 30, und sind so flexibel, dass man 135er- und 120er-Film darin entwickeln kann. Das Einspulen ist der einzige Schritt, wo man tatsächlich einen vollständig abgedunkelten Raum braucht. Eine Anleitung, wie das Einspulen geht, liegt bei, und selbst ich mit meinen halben Wurstfingern habe das bisher immer noch geschafft. Als abgedunkelten Raum verwende ich meine fensterlose Toilette, die nicht lichtdichten Schlitze decke ich mit Handtüchern ab. Das hat bisher noch immer funktioniert. Nach dem Einspulen die Dose schließen und fertig.
Das Entwickeln
Am einfachsten ist es, man besorgt sich einen Entwickler wie Rodinal (bzw. Entwickler "nach Agfa-Formel") und verdünnt die entsprechend der Anleitung mit handwarmem Wasser. Die genaue Wassertemperatur ist nicht wichtig, wenn man Leitungswasser verwendet, sollte man es so einstellen, dass es sich auf der Haut weder warm noch kalt anfühlt. Wer's genauer haben will, lagert einfach destilliertes Wasser in einem Raum, in dem ein Thermometer hängt, bei mir ist das z.B. das Badezimmer, das relativ konstant 21°C hat. Destilliertes Wasser hat noch andere Vorteile, dazu später mehr. Den verdünnten Entwickler füllt man in die Entwicklerdose, schließt die und folgt den Entwicklungsanweisungen, die sich auf der Entwicklerverpackung finden (z.B. "die erste Minute ständig kippen, danach alle 30 Sekunden"). Die Gesamtentwicklungsdauer für den passenden Film und die gewählte Entwicklerverdünnung kann man z.B. mit der Timer-Funktion von seinem Handy messen, danach Entwickler abgießen.
Das Stoppen
Stoppflüssigkeit ist Bullshit. Mit jedem Entwickler, mit dem ich bisher gearbeitet habe (Rodinal, und dann noch irgendein Auflöspulver von Ilford), hat es vollkommen genügt, zum Stoppen Wasser zu verwenden. Einfach ein paar Mal hintereinander Wasser einfüllen und wieder ausgießen, um die Entwicklerreste wegzuspülen.
Das Fixieren
Die Fixierflüssigkeit wird ähnlich wie der Entwickler zubereitet (die Verdünnungsverhältnisse und die empfohlenen Fixierzeiten stehen auch wieder auf der Verpackung), genauso eingefüllt und es wird analog gekippt und gewartet, dann ausgegossen.
Das Endwässern
Genauso wie das Stoppen mit Wasser, nur länger, um die Reste vom Fixierer zu entfernen.
Das Aufhängen und Trocknen
Normalerweise wird jetzt noch empfohlen, das ganze mit Netzflüssigkeit zu behandeln, damit das Wasser besser abrinnt. Das ist Bullshit. Ich hatte selbst mit dem relativ kalkhaltigen Berliner Wasser noch keine Probleme von Kalkflecken auf Film, wer ganz sicher gehen will, kann auch einfach als letzten Durchgang bei der Endwässerung destilliertes Wasser verwenden. Nach dieser (optionalen) Behandlung einfach den Film aus der Entwicklerdose nehmen, mit Wäscheklammern aufhängen (auch unten als Gegengewichte, damit sich der Film nicht einrollt und Wasser ordentlich abtropfen kann) und ein paar Stunden warten, bis der Film getrocknet ist. Dann den Film schneiden und einscannen, und fertig ist man.
Das Material
Hier ein paar Empfehlungen von Material, mit dem ich bisher gute Erfahrungen gemacht hab.
Entwicklerdose: dieses Modell bei Foto Impex genügt für 135er- und 120er-Film.
Entwickler: Rodinal ist in Ordnung. Ich verwende den " R09 One Shot", wie ihn Monochrom verkauft.
Fixierer: ich verwende derzeit Silberthio ph5, wie ihn Monochrom verkauft, vorher hatte ich den Ilford Rapid Fixer im Einsatz. Beide funktionieren.
Film: Ilford HP5, Kodak T-MAX 100 und 400 sind gut, wobei ich generell das Trägermaterial von Kodak etwas dünn finde, was das Handling beim Einscannen ein bisschen erschwert. Explizit abraten kann ich nur von den Fomapan-Film, die haben ein derartig grobes Korn, dass es zum Speiben ist. Die Filme sind nicht mal die wenigen Euro, die sie kosten, wert, höchstens als Experimentierfilm in Lochkameras o.ä.
Zusammenfassung
Letztendlich ist das Entwickeln von Schwarz-Weiß-Film deutlich leichter als vielfach nachzulesen, sofern man nicht dem Wahn verfällt, superexakt zu arbeiten. Schwarz-Weiß-Film hat sowieso soviel Spielraum, dass dies garnicht notwendig ist, und eigentlich nur dem Spaß verdirbt. Wen's interessiert, einfach ausprobieren. Für ganz Experimentierfreudige kann ich statt dem fertigen Entwickler was "selbstgepantschtes" empfehlen, und zwar Caffenol, das sind auf einen halben Liter Wasser acht Teelöffel Instantkaffee und zwei Teelöffel Soda (Natriumcarbonat), mit einer Entwicklungszeit von etwa 25 bis 30 Minuten.
Tuesday, April 13. 2010
synflood.at funktioniert wieder, inklusive der dazugehörigen Email-Adressen. Die Migration der Domain zu meinem Arbeitgeber war schwieriger als zunächst gedacht...
Saturday, January 23. 2010
Wie hier bereits vorher berichtet, ist meine Seagull eingegangen (naja, nicht so richtig, aber trotzdem tut sie nicht mehr so zuverlässig), als Ersatz dafür hab ich mir eine Yashica MAT 124 besorgt, durchchecken lassen, ein paar Monate damit Spaß gehabt, bis die Lufthansa die Kamera auf dem Weg von Berlin via Frankfurt nach Linz die Kamera im Gepäck zerstört hat. Und "zerstört" heißt: der Lichtschachtsucher ist abgerissen, insbesondere die Schrauben, die ihn am Gehäuse festgehalten haben, der Belichtungsmesser (das Highlight der Kamera) war eingedrückt, der Verschluss hat sich beim Auslösen nicht mehr geöffnet. Immerhin hat die Reiseversicherung, die bei der Kreditkarte dabei war, einen gewissen Teilbetrag anstandslos ausgezahlt.
Nun stand also eine Neubeschaffung im Raum, "tabula rasa", eine neue, robustere Mittelformatkamera. Ich hab mich die Tage davor schon informiert, was sich denn so alles tut auf dem Gebrauchtmarkt, und hatte ein paar verschiedene Modelle im Auge, von Zenza Bronica über Mamiya RB67 bis zu einer aufgemotzten Kiev 88 wie sie z.B. Wiese Fototechnik aus Hamburg vertreibt. Um mir mal ein wenig einen Überblick zu verschaffen, was sich auch bei den Fotohändlern so tut, bin ich gestern nachmittag dann auch noch zu Wüstefeld in Spandau gefahren, und habe dort - neben einigen eher uninteressanten MF-Kameras - ein Prachtstück gefunden, und zwar eine Mamiya C330 mit 80mm- und 135mm-Objektiv, in einem gut erhaltenen Zustand, zu einem so guten Preis, den ich sonst wo nirgendwo gesehen habe. Also hab ich mich spontan entschlossen, diese Kamera zu nehmen.
Die Mamiya C330 ist wie ihre zwei Vorgängerkameras eine TLR, also eine doppeläugige Spiegelreflexkamera, jedoch größer, robuster und schwerer als die meisten anderen Modelle dieser Bauart. Noch dazu hat die Mamiya C-Serie ein paar einzigartige Merkmale, die man sonst bei keiner anderen TLR findet. Zum einen ist es die einzige TLR-Modellserie mit Wechselobjektiven - während selbst Rolleiflex nur 80mm-Objektive drauf hat, kann man hier auf mehrere Objektive im Bereich von 55 bis 250mm zurückgreifen. Zum anderen ist die Kamera mit einem so riesigen Balgen ausgestattet, dass man selbst mit dem 80mm-Standardobjektiv sich mit der Linse bis auf ca. 15 cm an Objekte annähern kann (ein Korrekturfaktor zur eventuellen Anpassung von Blende oder Belichtungszeit wird im Sucher angezeigt). Außerdem findet man ein paar nette Features, so klappt etwa das hintere Teil zum Laden des Films nach unten statt wie sonst nach oben, was das Laden selbst deutlich erleichtert. Außerdem spult man mit einer Kurbel vor, wobei aber trotzdem die Möglichkeit für Mehrfachbelichtungen gegeben wird.
Insgesamt bin ich mit der Neuanschaffung ziemlich zufrieden, die Mamiya C330 scheint auf jeden Fall ein richtiges Arbeitstier zu sein. Morgen wird die Kamera von mir noch genauer ausgetestet werden.
Saturday, October 31. 2009
 Zum Beispiel, wenn man aus Interesse die defekte Mittelformatkamera ( ich hatte darüber berichtet) auseinandernimmt, und draufkommt, dass an dem Verschluss eigentlich garnichts kaputt ist, sondern dass lediglich ein Teil etwas geölt und eine bei einer früheren Reparatur falsch platzierte Trennscheibe wieder richtig platziert werden musste. Das hab ich gemacht, und jetzt funktioniert die Kamera wieder tadellos. argh Und das, nachdem ich so einen großen Aufwand betrieben habe, mir eine neue Kamera zu suchen und diese auch ordentlich warten zu lassen.
Naja, die nächsten Schritte werden jetzt wohl sein, dass ich die sauber entfernte Belederung wieder ebenso sauber anbringe (eine rein optische Sache, technische hat die keine Relevanz), sodass die Kamera wieder in einen verkaufsfähigen Zustand kommt, und möglicherweise werde ich die Kamera, nachdem ich ja mittlerweile besseren Ersatz habe, auch tatsächlich verkaufen.
|