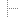Entries tagged as programming
Tuesday, December 18. 2012
Recently, I've been programming more and more in the Go programming language. Since my editor of choice has been vim for the last 10 years or so, I use vim to edit my Go code, as well. Of course, when I'm programming, I want my editor to support me in useful ways without standing in my way. So I took a look how I could improve my vim configuration to do exactly that.
The first stop is in the Go source tree itself. It provides vim plugins for syntax highlighting, indentation and an integration with godoc. This is a start, but we can go a lot further.
If you want auto-completion for functions, methods, constants, etc., then gocode is for you. After installation (I recommend installation via pathogen), you can use auto-completion from vim by pressing Ctrl-X Ctrl-O.
But with auto-completion, we can go even further: with snipmate, you have a number of things like if, switch, for loops that you can auto-complete by e.g. typing "if" and pressing the tab key. You can then continue pressing tab to fill out the remaining parts.
Another feature that I wanted to have as well was an automatic syntax check. For this task, you can use syntastic. But better configure it to passive mode and activate the active mode only for Go, otherwise other filetypes are affected as well. syntastic will call gofmt -l when saving a Go source file and mark any syntax errors it finds. This is neat to immediately find minor syntax errors, and thanks to Go's fast parsing, it's a quick operation.
Last but not least, I also wanted to have some features that aren't specific to Go: first, a file tree (but only if I open vim with no specific file), and second, an integration with ack to search through my source files efficiently and directly from vim. As a file tree, I found nerdtree to be quite usable, and as ack integration, I used this simple configuration snippet:
function! Ack(args)
let grepprg_back=&grepprg
set grepprg=ack\ -H\ --nocolor\ --nogroup
execute "silent! grep " . a:args
botright copen
let &grepprg=grepprg_back
endfunction
command! -nargs=* -complete=file Ack call Ack()
For my complete vim configuration, just take a look at it in my dotfiles repository. Enjoy!
Tuesday, May 8. 2012
Recently, I had quite a lot of free time to do stuff on my own. I'm currently unfit for work, and have been for over 2 months now, while I'm being treated for depression (don't worry, it's getting better).
To get myself going and get back on my feet, I started taking playing with technologies that I had recently read about, and built some simple things with them. As usual, I publish my works as open source. meta.krzz.de is one of these things. It's a meta URL shortener that will submit your URL shortening request to a number of URL shorteners in parallel, in display you the shortened URLs as they are received. See here for the source.
The interesting thing about this project is that it's essentially my first project involving AJAXy things and a shiny user interface (I used Bootstrap for the UI). I never really liked JavaScript, due to quite a few awkward language properties. Instead, I tried out Dart, a new language by Google that is meant as a replacement for JavaScript and currently provides a compiler to translate Dart code to JavaScript.
Dart is rather conventional. It obviously reminds one of Java, due to a very similar syntax. With its class system, it also provides compile-time checks that rule out a lot of errors beforehand. In addition, the generated code is meant to be quite portable, i.e. it should work with all/most modern browsers. Even though the documentation is terrible, I still found my ways a lot quicker than with my previous attempts with JavaScript. I got code running pretty quickly, had some first prototype, and from there on, it went quite fast. So Dart got me kind of hooked. Client-side web programming suddenly seemed easy.
So the next thing that I tried out was building a location hash router. The location hash is the part after the # sign that you may sometimes see in URLs. In recent times, it got more popular to keep the state of so-called single-page apps, web applications where all communication to the server is done using AJAX and the page is modified not by reloading but by modifying the DOM tree instead. You can find the source for hashroute.dart here.
The idea behind it is that you define a number of path patterns, Sinatra-style, e.g. /foo/:id, and callbacks that will be called whenever the location hash is set to a value that matches the pattern. When you look at the source, this is surprisingly simple and easy to understand.
And so I tried out another thing in Dart. David Tanzer recently told me about his idea of writing a blackboard application, where one user can draw something (his idea was using a tablet computer) and others can watch this in real time in their browser. After having a rough idea how I could implement that, I started a prototype with Dart on the client-side and Go on the server-side. You can find the source for the prototype here. The drawing is done on a HTML5 <canvas>. The Dart client not only allows the drawing, but records the coordinates for every stroke, and sends them to the server using WebSockets. The server takes these coordinates and forwards them to all listening clients, again via WebSockets. The "slave" is equally simple: it opens a WebSocket to the Go server and draws all incoming strokes according to the submitted coordinates. Currently, there is no authentication at all, and it's only a very early prototype, but this is not only a piece of code that (again surprisingly) simple, but also an idea that could evolve into a useful tool.
In total, I'm very satisfied with how straightforward Dart makes it to write client-side web applications. I've been pretty much a n00b when it came to the client side of the web, but with Dart, it feels accessible for me for the first time.
Sunday, October 9. 2011
A bit more than a year ago, I started baconbird, my first attempt at a Twitter client that fits my requirements. I worked on it for some time, and it reached a level where it was usable, and where I was pretty happy with it. But due to a few poor choices, chances for further development diminished, and I basically halted the project, and only used the software. And after using it for a few months, more and more principal defects, practically unfixable, came up. Just too much began to suck, so earlier this week, I decided to throw baconbird away and reboot the whole project.
But first things first: my first poor choice was using Perl. Sure, Perl provided me with all the tools to come to meaningful results really quickly, through the vast amount of ready-to-use modules in the CPAN archive. And that's what's really great about it. What's not so great about Perl are the ideas of concurrency. You basically have to resort to event-based, async-I/O programming, which is not only painful by itself, but also extremely painful to integrate with my widget set of choice, STFL. And threads in Perl... don't do it, that's what everyone says. That meant that I couldn't do any of the Twitter communication asynchronously in the background, but had to do it in my primary thread of execution, essentially make it part of the subsequent calls of the input loop, if I wanted to retain sanity and a certain level of productivity. And that made baconbird really slow to use, and when Twitter's API was offline, baconbird practically hung. That made baconbird just a PITA to use, and I had to change something about it.
Also, in the last few months, I played more and more with Go, a programming language developed by several people at Google, many of which were formerly involved in projects like Unix or Plan 9. I became more fluent in it, and I really liked the concepts of Go about concurrency, parallelism and IPC. Also, I played with Go's foreign function interface, cgo, and built a wrapper around STFL so that it could be used with Go. So, essentially, Go would provide me with a few language features that I totally missed in Perl, while it wouldn't provide me with other niceties, like a CPAN-like repository. But finally, I decided to just bite the bullet, at least build upon an existing OAuth implementation for Go, and started my second incarnation of an STFL-based Twitter client, this time written in Go. And, after some initial prototyping that started last Thursday, I put more work into it this Saturday and Sunday, and today I reached the point where I had some code to show that wasn't completely ugly, had some structure and the basic outlines of an architecture, and that obviously didn't suffer from all the negative things that I hated about baconbird.
The overall structure is simple: three goroutines are started, one for the model (which does all the interaction with the Twitter API), one for the controller (which, now that I think about it, may be obsolete, because it doesn't do that much except for receiving new tweets and sending them to the UI), and one for the user interface (which does all the non-interactive redrawing and UI fiddling). Reading the user input is done in the main execution thread of the program, but no parsing is done and all input is given directly to the user interface goroutine. As already suggested, these three goroutines communicate using channels. When the model receives new tweets, it sends them to the controller, the controller puts them into a list of all tweets and then forwards them to the user interface, and the user interface inserts them into the list of tweets that are displayed to the user. And when a new tweet is sent, the text for it is read by the user interface, but is then sent to the model (again via a channel; i.e. the application won't block while the tweet is being transmitted to Twitter), and when sending the tweet is finished, the Twitter API returns the tweet object, which is then again handed over to the controller and the user interface (so that you can immediately see your own tweet in your home timeline as soon as it's reached Twitter). That's basically all the functionality that's there, but there's a lot more to come.
And before I forget it: the code is already out there. Visit gockel ("Gockel" means "rooster" in German, which is a type of bird [Twitter, bird, you know], and I chose it because the first two letters also give a hint about the programming language in which it is being developed), and read the source code, which I consider to be rather simple and easy to understand. A lot more will change, new features, everything will be better, and hopefully soon, gockel will be ready to achieve world domination. No, seriously: this reboot finally gives me the ability to (hopefully) implement the Twitter Streaming API with only minimal amounts of pain.
Tuesday, July 5. 2011
In the last few months, from time to time I experimented with the programming language Go, a new systems language released only in 2009 and developed by people like Ken Thompson, Rob Pike and Russ Cox at Google. While still staying relatively low-level, it adds a garbage collector, and simple object/interface system, and the mechanisms of goroutines and channels as means of concurrency and inter-process communication (or should I say inter-goroutine communication).
In the last few days, I found more time to experiment with Go, and finally fully got the hang of the object system, and I must say that I really like it, both for the simplicity and the expressiveness. Objects in Go feel so simple, so natural, and at the same time powerful, with very little syntactic overhead. So that's what I want to write about today.
Let's start with a simple example:
Here we created a new type Vehicle with one private member "speed", and a method Speed() that returns the current speed. Of course, a vehicle all by its own isn't very useful, so we define the minimal requirements for a vehicle that's actually usable:
Here we define an interface named Drivable that defines the required methods for an object to be drivable, in our case, it must be able to accelerate, brake and show the current speed. Based on this, we construct our first actually usable vehicle:
And voila, we have our first Car that is also Drivable. What did we exactly do here?
We created a new type Car that is a struct, and embedded the type Vehicle: instead of adding a named member, we added an unnamed member, only specified by the type. This embedding also makes all available methods for this type available to our new type, i.e. a method Speed() is now also available for our type Car.
In addition, we implemented two new methods, Accelerate() and Brake(), in order to match the interface Drivable. And last but not least, we implemented a function to create a new Car.
Now, let's create another type of Drivable vehicle, let's say a boat:
So far, so uninteresting. The implementation of the boat is basically the same as the car, so nothing new.
But now I want to go a step further and implement and amphibious vehicle that is both a car and a boat. Let's just do that:
But that doesn't quite work out, because when we try to compile it, we will see an error message like this:
Since we embedded both Car and Boat into Amphibian, the compiler can't decide which Accelerate() method it shall use, thus communicating it as ambiguous. Based on that, it also says that it can't create an object of type Amphibian as Drivable because it has no proper Accelerate() function. This is the classic problem of diamond inheritance that we need to resolve here, not only for Accelerate(), but also for Brake() and Speed(). In the case of the amphibious vehicle, we do this by returning the right speed depending on whether the vehicle is in the water or on land:
And of course, the object perfectly works as Drivable:
So, what I just showed you are the capabilities in what Go modestly calls embedding but that feels like multiple inheritance and is really simple at the same time.
For a more complete view on Go and its features, I recommend the official Go documentation, and especially " Effective Go", a document that introduces the most important Go features and shows how to write idiomatic Go code. The complete example source code can be found here.
Monday, January 10. 2011
In this posting (and also this one), Su-Shee pleads for a more vocal and active promotion/advocacy. While I know how nice it can be to use a piece of software that makes people envious, I just want a quiet, hype-free, pragmatic, down-to-earth knowledgable community, and I will explain why.
Some years ago, summer or fall 2002, if I recall correctly, there was this new object-oriented programming language that everybody was talking about, that was quite obscure but really cool because you could write compact, easy-to-read, object-oriented code, in a fashion not unlike Perl. That programming language was Ruby. Having had a background of Pascal, C, and some C++ and Perl, I was astonished by the expressiveness and flexibility of the language, without losing readability. I used Ruby for quite some time, worked on some silly open source project with it, I used it for scripting at work (until my then-boss prohibited the use of any programming language for which no other developer in-house had any knowledge), I wrote daemons that formed the glue between email and MMS systems, I even used it as exploratory prototyping language for stuff that I would later rewrite in C. And then came Rails.
Rails was hyped as the greatest invention since sliced bread, the be-all end-all of web development. As somebody who had previously only known CGI.pm and cgi.rb, this indeed looked intriguing. I had a closer look, bought a book, played with it, and found it quite OK. Until I wanted to do things differently than what the usual tutorials had in mind. Useful documentation about the greater context and overall concepts was sparse (be aware, this was pre-1.0 Rails, things may have changed a lot since then), and I felt constricted by too many things in Rails (this has most likely been addressed in later releases; I haven't bothered to look back since then, though). So many things that were advertised as awesome turned out to be nice, but not that impressive on closer inspection.
And this is exactly what I don't want to do, namely awakening false hope in people about awesome features of $SOFTWARE, and I think an overly optimistic presentation of a system's features can easily lead to exactly that. In fact, the only screencast that didn't disappoint on closer look was Google's launch of the Go programming language in 2009, but that only as a side note. Self assurance is nice at all, but in my experience, there's only a fine line between self assurance and misrepresentation.
Another aspect of the Rails hype was the complete turn-over of a great portion of the Ruby community. The usual community and support channels were flooded with people interested in Rails, Rails became synonymous with Ruby, the signal-noise ratio drastically became worse. Some people even tried to actively recruit me for open-source Rails projects because I "knew Ruby". I declined, because the web applications aren't my area of interest at all (even today, the only things I have to do with web is that I hack on stuff like Apache and PHP [the interpreter] for a living; still, no web development).
Yeah, the community turn-over. Soon, people with big egos and great self assurance surfaced, dubbing themselves rockstars or ninjas or similar. I always found these to be acts of total douchebaggery, because, in the end, they all only cooked with water, anyway (a notable exception was why the lucky stiff). These were the people with great self assurance and a total lack of self-criticism or reflection on one's own work. It's not the kind of people whose software I would want to use, because too often my experience was that some library, framework or tool was announced with big words, which then practically always turned out not to be great at all, sometimes even barely usable or totally buggy.
And that brings me back to the original topic of Perl. Exactly the things that I learned to despise about the culture revolving around Ruby and Rails are something that I haven't experienced in the Perl community at all so far. Libraries, framework, documentation and people had more time to mature, probably, while still being down-to-earth. I can expect good documentation, functioning software, friendly people and most importantly accurate words in announcements and discussions.
Through my current employment, I found the way back to Perl, using it at work and also for some personal stuff. I recently even started a new open source project where I productively use Moose for the first time. My code is probably not very expressive and may seem weird (I know, TIMTOWTDI), but at least I feel comfortable writing it. I'm fine with most things surrounding Perl, its eco-system and its communities, and so I don't want to see any kind of interruption and turn-over like I saw it with Ruby.
Thursday, July 22. 2010
Introduction
In the beginning, there was char. It could hold an ASCII character and then some, and that was good enough for everybody. But later, the need for internationalization (i18n) and localization (l10n) came up, and char wasn't enough anymore to store all fancy characters. Thus, multi-byte character encodings were conceived, where two or more chars represented a single character. Additionally, a vast set of incompatible character sets and encodings had been established, most of them incompatible to each other. Thus, a solution had to be found to unify this mess, and the solution was wchar_t, a data type big enough to hold any character (or so it was thought).
Multi-byte and wide-character strings
To connect the harsh reality of weird multi-byte character encodings and the ideal world of abstract representations of characters, a number of interfaces to convert between these two was developed. The most simple ones are mbtowc() (to convert a multi-byte character to a wchar_t) and wctomb() (to convert a wchar_t to a multi-byte character). The multi-byte character encoding is assumed to be the current locale's one.
But even those two functions bear a huge problem: they are not thread-safe. The Single Unix Specification version 3 mentions this for wctomb, but not for mbtowc, while glibc documentation mentions this for both. The solution? Use the equivalent thread-safe functions mbrtowc and wcrtomb. Both of these functions keep their state in a mbstate_t variable provided by the caller. In practice, most functions related to the conversion of multi-byte strings to wide-character strings and vice versa are available in two versions: one that is simpler (one function argument less), but not thread-safe or reentrant, and one that requires a bit more work for a programmer (i.e. declare mbstate_t variable, initialize it and use the functions that use this variable) but is thread-safe.
Coping with different character sets
To convert different character sets/encoding between each other, Unix provides another API, named iconv(). It provides the user with the ability to convert text from any character set/encoding to any other character set/encoding. But this approach has a terrible disadvantage: in order to convert text of any encoding to multi-byte strings, the only standard way that Unix provides is to use iconv() to convert the text to the current locale's character set and then convert this to a wide-character string.
Assume we have a string encoded in Shift_JIS, a common character encoding for the Japanese language, and ISO-8859-1 (Latin 1) as the current locale's character set: we'd first need to convert the Shift_JIS text to ISO-8859-1, a step that is most likely lossy (unless only the ASCII-compatible part of Shift_JIS is used), and only then we can use to mb*towc* functions to convert it to a wide-character string. So, as we can see, there is no standard solution for this problem.
How is this solved in practice? In glibc (and GNU libiconv), the iconv() implementation allows the use of a pseudo character encoding named "WCHAR_T" that represents wide-character strings of the local platform. But this solution is messy, as the programmer who uses iconv() has to manually cast char * to wchar_t * and vice versa. The problem with this solution is that support for the WCHAR_T encoding is not guaranteed by any standard, and is totally implementation-specific. For example, while it is available on Linux/glibc, FreeBSD and Mac OS X, it is not available on NetBSD, and thus not an option for truly portable programming.
Mac OS X (besides providing iconv()) follows a different approach: in addition to the functions that by default always use the current locale's character encoding, a set of functions to work with any other locale is provided, all to be found under the umbrella of the xlocale.h header. The problem with this solution is that it's not portable, either, and practically only available on Mac OS X.
Alternatives
Plan 9 was the first operating system that adapted UTF-8 as its only character encoding. In fact, UTF-8 was conceived by two principal Plan 9 developers, Rob Pike and Ken Thompson, in an effort to make Plan 9 Unicode-compatible while retaining full compatibility to ASCII. Plan 9's API to cope with UTF-8 and Unicode is now available as libutf. While it doesn't solve the character encoding conversion issue described above, and assumes everything to be UTF-8, it provides a clean and minimalistic interface to handle Unicode text. Unfortunately, due to the decision to represent a Rune (i.e. a Unicode character) as unsigned short (16 bit on most platforms), libutf is restricted to handling Unicode characters of the Unicode Basic Multilingual Plane (BMP) only.
Another alternative is ICU by IBM, a seemingly grand unified solution for all topics related to i18n, l10n and m17n. AFAIK, it solves all of the issues mentioned above, but on the other side, is perceived as a big, bloated mess. And while its developers aim for great portability, it is non-standard and has to be integrated manually on the respective target platform(s).
Saturday, August 30. 2008
Schon seit einiger Zeit hege ich den Wunsch, funktionale Tests von newsbeuter durchzuführen, indem ich das ncurses-Interface von newsbeuter direkt treibe. Nur so ist es möglich, auch die ganze Logik, die zwangsweise im User Interface steckt, zu testen, und "Umfaller", wie sie in der Vergangenheit immer wieder passiert sind, künftighin zu erkennen. Nachdem ich für diese Aufgabe kein passendes Tool gefunden habe, bin ich nun endlich daran gegangen, selbst eine Lösung zu entwickeln. Herausgekommen ist "tuitest", ein Testing Tool für Text User Interfaces.
tuitest besteht aus zwei Komponenten, und zwar einerseits ein Recorder, der die Application under Test (AUT) in einem fixen 80x25-Terminal startet, und sämtliche Interaktionen mit der Applikation aufzeichnet, und daraus ein Ruby-Skript generiert, und andererseits ein Ruby-Modul, das Hilfsfunktionen zur Ausführung und Verifikation der Programmausgabe anbietet. Diese Hilfsfunktionen werden im vom Recorder generierten Skript verwendet.
Die Bedienung ist denkbar einfach: auf der Kommandozeile startet man den Recorder mit tt-record scriptname.rb 'commandline mit parametern', bedient die Teile der AUT, die man testen will, und beendet sie wieder. Die aufgezeichnete Interaktion wird in scriptname.rb gespeichert, und kann über ruby scriptname.rb sofort ausgeführt werden. Teile eines derartig erstellten Skripts sehen so aus: Tuitest.keypress("r"[0]) Tuitest.wait(1244) Tuitest.keypress(258) Tuitest.wait(473) Tuitest.keypress("r"[0]) Tuitest.wait(3453) Tuitest.keypress(259) Tuitest.wait(2215) Tuitest.keypress(10) Tuitest.wait(5702) Tuitest.keypress("A"[0]) Tuitest.wait(980)
Um das korrekte Verhalten des Programms anhand des User Interface auch überprüfen zu können, erlaubt tuitest, Verifications durchzuführen. Hierbei wird überprüft, ob sich an gewissen Positionen des Terminals ein bestimmter Text befindet. Schlägt diese Überprüfung fehl, so wird die Ausführung abgebrochen. Alternativ gibt es einen "soften" Ausführungsmodus, wo bei einer fehlgeschlagenen Überprüfung lediglich eine Warnung geloggt wird.
Verifications kann man entweder händisch nach Aufzeichnung des Skripts einfügen, oder aber vom Recorder automatisch generieren lassen: vor einer Operation, deren Ergebnis überprüft werden soll, nimmt man einen Snapshot des Terminals, mit Hilfe der Taste F5. Dann führt man die Operation aus. Ist diese beendet, so drückt man die Taste F6. Es wird wieder ein Snapshot genommen, und die Unterschiede zwischen dem vorigen Snapshot und dem letzten Snapshot werden als Verifications automatisch geskriptet. Diese generierten Verifications bilden i.A. eine gute Basis für weitere, manuelle Verfeinerungen. Verifications sehen folgendermaßen aus: # begin auto-generated verification #1 verifier.expect(0, 65, "0 unread, 10 to") verifier.expect(1, 5, " ") verifier.expect(2, 5, " ") verifier.expect(3, 5, " ") verifier.expect(4, 5, " ") verifier.expect(5, 5, " ") verifier.expect(6, 5, " ") verifier.expect(7, 5, " ") verifier.expect(8, 5, " ") verifier.expect(9, 5, " ") verifier.expect(10, 5, " ") # end auto-generated verification #1
Standardmäßig laufen die Verifications im "harten" Modus, d.h. ein Fehler führt zum Abbruch. Um den "soften" Modus zu aktivieren, ist als letzter Parameter zu einem verifier.expect Aufruf noch ":soft" (ohne Anführungszeichen) hinzuzufügen.
Die Ausführung schneller machen
Standardmäßig findet die Ausführung in exakt dem Timing statt, in dem auch die Aufzeichnung durchgeführt wurde. Oftmals will man dies für automatisierte Tests überhaupt nicht, denn diese sollen so schnell wie möglich ablaufen. tuitest bietet dafür Hilfsfunktionen, um manuelle Optimierungen möglich zu machen, und zwar mit einer Funktion Tuitest.wait_until_idle. Diese Funktion wartet so lange, bis sich länger als eine Sekunde nichts am Terminal geändert hat. Sinnvoll ist, einen Tuitest.wait_until_idle Call beim Programmstart einzufügen, dann die Key-Presses so schnell wie möglich auszuführen (d.h. die Tuitest.wait Calls zu entfernen), und dann vor einer Verification wiederum mit wait_until_idle zu warten, um der AUT die Möglichkeit zu geben, die extrem schnellen Eingaben "aufzuholen". Damit ist es möglich, die Ausführung deutlich schneller zu machen, und trotzdem die Stabilität der Tests nicht zu gefährden.
Wer sich mit tuitest spielen will, der muss sich bis jetzt mit der aktuellen Version aus dem Subversion-Repository begnügen. Die Dokumentation ist bisher noch etwas dürftig, aufgezeichnete Skripte sollten aber halbwegs selbsterklärend sein. Und nachdem das Ausgabeformat ja ein Ruby-Skript ist, kann man damit mehr machen als nur Tests - im Grunde genommen sind jegliche Automatisierungen von v.a. ncurses-basierten Programmen möglich. Und wie immer ist Feedback herzlich willkommen.
Sunday, June 22. 2008
Learned basic C++ from an inadequate tutorial.
#include <iostream.h> using namespace std; // thanks, joe void main(int argc, char** argv) { cout << "Hello, world!" << endl; }
#include <iostream> using namespace std; int main(int argc, char* argv[]) { cout << "Hello, world!" << endl; return 0; }
#include <iostream> int main(int argc, char* argv[]) { std::cout << "Hello, world!" << std::endl; return 0; }
#include <iostream> #include <string.h> class Hello { private: char* msg; public: Hello() { this->msg = strdup("Hello, world!"); } ~Hello() { delete this->msg; } char* hello() { return this->msg; } }; int main(int argc, char* argv[]) { Hello* hello = new Hello(); std::cout << hello->hello() << std::endl; delete hello; return 0; }
#include <iostream> #include <string> class Hello { private: std::string msg; public: Hello() { this->msg = "Hello, world!"; } std::string hello() { return this->msg; } }; int main(int argc, char* argv[]) { Hello hello; std::cout << hello.hello() << std::endl; return 0; }
/usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/bits/ios_base.h: In copy constructor ‘std::basic_ios<char, std::char_traits<char> >::basic_ios(const std::basic_ios<char, std::char_traits<char> >&)’: /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/bits/ios_base.h:783: error: ‘std::ios_base::ios_base(const std::ios_base&)’ is private /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/iosfwd:52: error: within this context /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/iosfwd: In copy constructor ‘std::basic_ostream<char, std::char_traits<char> >::basic_ostream(const std::basic_ostream<char, std::char_traits<char> >&)’: /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/iosfwd:61: note: synthesized method ‘std::basic_ios<char, std::char_traits<char> >::basic_ios(const std::basic_ios<char, std::char_traits<char> >&)’ first required here test.cpp: In function ‘int main(int, char**)’: test.cpp:7: note: synthesized method ‘std::basic_ostream<char, std::char_traits<char> >::basic_ostream(const std::basic_ostream<char, std::char_traits<char> >&)’ first required here test.cpp:7: error: initializing argument 3 of ‘_Funct std::for_each(_IIter, _IIter, _Funct) [with _IIter = __gnu_cxx::__normal_iterator<char*, std::basic_string<char, std::char_traits<char>, std::allocator<char> > >, _Funct = std::basic_ostream<char, std::char_traits<char> >]’ /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/bits/stl_algo.h: In function ‘_Funct std::for_each(_IIter, _IIter, _Funct) [with _IIter = __gnu_cxx::__normal_iterator<char*, std::basic_string<char, std::char_traits<char>, std::allocator<char> > >, _Funct = std::basic_ostream<char, std::char_traits<char> >]’: test.cpp:7: instantiated from here /usr/lib/gcc/x86_64-unknown-linux-gnu/4.3.1/../../../../include/c++/4.3.1/bits/stl_algo.h:3791: error: no match for call to ‘(std::basic_ostream<char, std::char_traits<char> >) (char&)’
#include <iostream> #include <string> #include <vector> int main(int argc, char* argv[]) { std::string hello = "Hello, world!"; std::vector<char> v; for (unsigned int j = 0; j < hello.length(); ++j) { v.push_back(hello[j]); } std::vector<char>::iterator i; for (i = v.begin(); i != v.end(); ++i) { std::cout << <strong>i; } std::cout << std::endl; return 0; }
#include <iostream> #include <string> #include <algorithm> class printc { public: void operator() (char c) { std::cout << c; } }; int main(int argc, char</strong> argv[]) { std::string hello = "Hello, world!"; std::for_each(hello.begin(), hello.end(), printc()); std::cout << std::endl; return 0; }
#include <iostream> int main(int argc, char* argv[]) { std::cout << "Hello, world!" << std::endl; return 0; }
#include <stdio.h> int main(int argc, char* argv[]) { printf("Hello, world!\n"); return 0; }
HAI
CAN HAS STDIO?
VISIBLE "HAI WORLD!"
KTHXBYE
Found a replacement for /b/ after finding it overrun by ``cancer'' and ``newfags.''
One word, the forced indentation of code. Thread over. Also, read SICP!
Read SICP after months of telling people to read SICP.
(display "Hello, world!") (newline)
void main() { puts("Hello, world!"); }
(gefunden irgendwo auf 4chan, Dank an nion)
Thursday, April 17. 2008
There are certain C standard library functions whose potentially insecure behaviour is well known. These functions, such as sprintf() or strcpy() are usually avoided these days. But today, while reviewing some security-related code, that there is one function where you wouldn't really expect any weird oder unusual behaviour. The function that I'm talking about is strtoul().
Most people will automatically know and/or associate that it's the unsigned long variant of the strtol() function that is used to convert strings to integers. Some may also think about using this function to verify that the result of the string to integer conversion can never be negative, and thus, strtoul() completely ignores negative numbers. But this is wrong: strtoul() does check for a + or - sign, and if it finds a "-" before the actual number to be converted, it negates the the scanned value prior to returning it. That's what the manpage and the official SuSv2/v3 documentation say, and it sounds innocuous. But it definitely isn't, and this little test program will show this: #include <stdio.h> #include <stdlib.h> #include <limits.h> #include <errno.h> int main(int argc, char * argv[]) { char * endptr; unsigned long int value; value = strtoul(argv[1], &endptr, 10); if (value == ULONG_MAX) { } return 0; }
Let's see how this program behaves when feeding it some numbers: To sum this up: - Positive numbers are scanned correctly, except for ULONG_MAX.
- Negative numbers are scanned, and their (negative) value is casted to an unsigned type. In the case of -1 that becomes 4294967295, this also (incorrectly) signals an error during conversion, in the case of -2 it doesn't.
- Numbers that are too large are signaled as such.
In my opinion, this behaviour is clearly unacceptable, as it is completely counter-intuitive, it can lead to incorrect error signaling, and is a hazard for anybody who wants to stick to unsigned integers only. It's nothing but a thinly disguised (unsigned long)strtol(...). So don't use it. Use strtol() and explicitly manually exclude negative values instead, and explicitly cast it to an unsigned value afterwards. That limits the maximum value that you can scan, but hey, the world isn't perfect.
Wednesday, February 13. 2008
Weil es immer wieder zur Sprache kommt, auch in meiner Arbeit (obwohl wir keine Raketenwissenschaftler sind, und kein Ada programmieren), hier findet sich eine Seite mit einer ziemlich guten Beschreibung, was denn genau schief gelaufen ist beim ersten Start der Ariane 5. Und hier das Code-Snippet: declare vertical_veloc_sensor: float; horizontal_veloc_sensor: float; vertical_veloc_bias: integer; horizontal_veloc_bias: integer; ... begin declare pragma suppress(numeric_error, horizontal_veloc_bias); begin sensor_get(vertical_veloc_sensor); sensor_get(horizontal_veloc_sensor); vertical_veloc_bias := integer(vertical_veloc_sensor); horizontal_veloc_bias := integer(horizontal_veloc_sensor); ... exception when numeric_error => calculate_vertical_veloc(); when others => use_irs1(); end; end irs2;
Thursday, January 31. 2008
Dear Sam,
Although what you describe comes quite close to CI, it isn't. Unless you compile the code and run the test suite in a clean and neutral build environment, you can never be sure that the changes you're about to commit really do integrate properly. Even if you do a svn/cvs update (or the equivalent command of your favorite SCM) before you compile, run the tests and commit, you'll never know whether it compiles in other build environments. Perhaps you've forgotten to add a file to be committed, perhaps you've relied on certain specifics of your local system when tweaking something on the Makefiles. People make these mistakes all the time, and that's why we shouldn't rely on people running test suites locally.
That's what CI system like CruiseControl or Hudson are there for: they rebuild the software and run the test suite in a clean environment (ideally) whenever a commit is done, in continuous iterations, automatically, without any manual intervention by the programmer. With such simple little helpers combined with some notification, such integration mistakes or any other regressions that can be caught with the existing test suite wouldn't go unnoticed. Hey, you could even send notification emails about build and/or test failures (including their recoveries) to a public mailing list, which would dramatically increase the visibility of such automatized efforts.
If you already do so, I apologize for my possibly rude tone, but your article suggests that you don't.
Sunday, November 25. 2007
Nach schätzungsweise 6 Jahren Pascal-Abstinenz hab ich letzten Freitag abend/nachmittag wieder ein paar Zeilen Pascal-Code geschrieben, um meine Kenntnisse wieder etwas aufzufrischen. Und nun bin ich erstaunt, wie schnell und produktiv man in Pascal vorankommt und produktiv sein kann. Wer den Code sehen will, der sehe ihn sich bitte hier an. Es handelt sich um eine Implementierung von RFC 569. So richtig sinnvoll ist der Code nicht (jeder noch so einfache Editor heutzutage hat 10mal mehr Funktionalität und Komfort), aber ein gute Aufgabe, um einen Nachmittag mit der Ausimplementierung zu füllen.
Übrigens, das meiner Erfahrung nach bessere freie Pascal-System ist Free Pascal. GNU Pascal ist im Gegensatz dazu etwas buggy (auch wenn darum workarounden kann), und generiert wesentlich größere Binaries als Free Pascal.
Sunday, November 4. 2007
Es ist immer wieder praktisch, die Code Coverage von Programmen bei automatischen und manuellen Tests zu bestimmen, um feststellen zu können, welche Codeteile getestet und welche nicht getestet sind. Die GNU-Lösung für Code Coverage ist GCOV, ein eher krudes Commandline-Tool. Mir persönlich ist das Tool bei weitem nicht mächtig genug, und so habe ich heute LCOV, ein Wrapper um GCOV, der nicht nur farblich ansprechende und übersichtliche Ausgaben zur Code Coverage generiert, sondern mit dem es auch möglich ist, die Code Coverage von verschiedenen Testläufen problemlos zu akkumulieren. Und zwar geht das so:
Zuerst compiled man das zu testende Programm mit den CFLAGS (bzw. CXXFLAGS) "-fprofile-arcs -ftest-coverage". Dann lässt man das Programm laufen, und führt seine Tests durch (z.B. typische Use-Cases, oder aber auch ausprobieren aller vorhandenen Features, oder ...), und am Ende sammelt man die von GCOV geschriebenen Ergebnisse mit "lcov -d . -b . -o programm.info". Dann kann man einen weiteren Testlauf starten, z.B. Unit-Tests, oder einen anderen Use-Case, und mit einem weiteren Aufruf von "lcov -d . -b . -o programm.info" wird die Coverage dieses Testlaufs gesammelt. Wenn man dann alle Testläufe abgeschlossen hat, kann man aus dern Datei programm.info, welche die akkumulierte Code Coverage des getesteten Programms enthält, schöne übersichtliche Charts generieren, und zwar mit "genhtml programm.info". Man kann auch nach jedem Testlauf und Sammeln der Ergebnisse die HTML-Files generieren, um daraufhin für den nächsten Testlauf entscheiden zu können, welche Features noch genauer zu testen sind, usw. usf. Auf jeden Fall ist LCOV meiner heutigen Erfahrung nach wesentlich übersichtlicher und angenehmer, als GCOV per Hand zu bedienen.
Tuesday, October 23. 2007
Auf die wirklich ekligen Sachen kommt man erst drauf, wenn man versucht, Unix-Legacy-Code auf einem aktuellen Linux oder OSX zum Laufen zu bringen. Da bin ich z.B. draufgekommen, dass es in C unter Linux ein Symbol "end" gibt (wer es zur Verfügung stellt, konnte ich ad hoc nicht rausfinden), auf jeden Fall muss man es nur deklarieren, und schon ist es verwendbar: #include <stdio.h> extern char end[1]; int main(void) { return 0; }
Draufgekommen bin ich darauf nur, weil ich sort(1) von Ultrix-11 auf Linux portiert habe, und diesen Code wiederum unter OSX zum Laufen bringen wollte. Und dabei ist mir folgender Code untergekommen: #define MEM (16*2048) /* ... */ char *ep; /* ... */ ep = end + MEM; /* ... */ while((int)brk(ep) == -1) ep -= 512; #ifndef vax brk(ep -= 512); /* for recursion */ #endif
Dieser Code legt nahe, dass "end" das aktuelle Ende des Datensegments enthält, und obiger Code holt sich das Ende, zählt einen großen Betrag (für damalige Zeiten...) dazu, und verringert ihn solange um 512 (welche Einheit?), bis brk(2) OK gegangen ist, und das Datensegment vergrößert ist. Sowas ist in Zeiten von 4GB+ RAM und Memory Overcommitment natürlich höchst obsolet. Trotzdem ist es bemerkenswert, wie damals(tm) noch programmiertechnisch gearbeitet wurde.
Tuesday, August 7. 2007
Bisher sind schon mehrere Leute auf mich zugekommen, sie wollen doch eine Art "Meta-Feed" in newsbeuter, der alle ungelesenen Feeds enthält. Diesem Wunsch bin ich heute nachgekommen, und hab das gleich schön generalisiert, d.h. jeder Benutzer kann sich seine eigenen Meta-Feeds ("query feeds" im newsbeuter-Jargon) definieren, und zwar auf Basis der newsbeuter-internen Filtersprache. Das funktioniert relativ einfach: man füge einfach eine neue Konfigurationszeile in die Datei ~/.newsbeuter/urls ein, welche mit "query:" beginnt, dann den Namen enthält, auf welchen - durch einen Doppelpunkt getrennt - ein Filterausdruck folgt. Startet man nun newsbeuter, so sieht man diesen neuen Eintrag in der Liste der Feeds, mit dem konfigurierten Namen. Öffnet man diesen Feed, so werden alle heruntergeladenen Artikel, auf die der angegebene Filterausdruck zutrifft, in der Artikelübersicht angezeigt. Der "Klassiker", also die öfter geforderte Funktionalität, alle ungelesenen Artikel aller Feeds anzuzeigen, sieht dann in der Konfiguration so aus:
"query:Unread Articles:unread = \"yes\""
Man achte auf das Quoting: da die pseudo-URL Leerzeichen enthält, muss diese als ganze gequoted werden. Da im Filterausdruck ebenfalls Quotes vorkommen, müssen diese passend escaped werden. Ganz praktisch auch das Zusammenfassen von mehreren mit dem selben Tag versehenen Feeds zu einem einzigen Feed:
"query:gesammelte Artikel:tags # \"tagname\""
Im Grunde genommen sind die Möglichkeiten der Query Feeds nur eingeschränkt durch die mit der Filtersprache abfragbaren Attribute und die eigene Kreativität.
Die Query Feeds werden Teil des nächsten Releases sein, das diesmal weniger lang auf sich warten lassen wird als das letzte Release 0.5. Zusätzliche Features werden da u.a. auch das Neuladen des urls-File von newsbeuter aus (Kleinigkeit, aber trotzdem praktisch) und eine Eingabe-History für die Filtereingabefelder und die interne Kommandozeile sein.
|