Entries tagged as newsbeuter
Monday, July 12. 2010
OpenBSD ist - wie dem einen oder anderen Leser sicherlich bekannt sein dürfte - ein von NetBSD abgeleitetes Unix-artiges Betriebssystem, das seinen Fokus auf Sicherheit legt. Als Entwickler und Maintainer des mittlerweile halbwegs populären Open-Source-Projekts newsbeuter sehe ich es nicht nur als meine Aufgabe, neue Features zu entwickeln und bestehende Bugs zu fixen, sondern auch einen gewissen Aufwand darin zu stecken, die Software für ein möglichst großes Publikum auch tatsächlich praktisch zugänglich zu machen. Diese Aufgabe hat verschiedene Grundrichtungen. Das ist etwa die einfache Verfügbarkeit für Enduser (da habe ich beispielsweise vor kurzem erst eine Liste von Distributionen, die mit fertigen Paketen kommen, zusammengestellt), eine möglichst durchgängige Internationalisierung und Lokalisierung (so ist newsbeuter in mittlerweile 14 verschiedenen Sprachen verfügbar), oder aber auch, die Kompatibilität zu anderen Systemen als nur die populären Linux-Distributionen zu testen und zu gewährleisten. Letzteres hat dazu geführt, dass newsbeuter unter Linux, FreeBSD und Mac OS X läuft.
Vergangenes Wochenende habe ich mich daran gemacht, die Kompatibilität auch zu weiteren Systemen zu testen. Auf meinem Plan standen konkret NetBSD und OpenBSD. Der Zustand von NetBSD ist kurz geschildert der, dass die Citrus-Implementierung von iconv() in der Art und Weise nicht kompatibel ist, als dass es das spezielle Encoding "WCHAR_T", das von der STFL verwendet wird, nicht unterstützt. Das ist nicht schön, aber verkraftbar, da einerseits die von iconv unterstützten Encodings/Zeichensätze systemspezifisch sind, andererseits man da sicherlich auch (achtung, ungetestet!) die GNU libiconv einsetzen könnte.
Bei OpenBSD bietet sich hier ein völlig anderes Bild: hier scheiterte mein Versuchen, die STFL zu übersetzen, schon daran, dass OpenBSD über keine Implementierung von swprintf verfügt. Etwas verdutzt hab ich dann begonnen, weiterzurecherchieren, weil ich eigentlich der Meinung war, dass OpenBSD eigentlich schon mal die Arbeit des Citrus-Projekts importiert hatte, und bin schon nach kurzem über die nahezu talibanesken Ausführungen eines Herrn uriel, der einen Fanatismus dabei zeigt, auf den Unix-Standardweg für Internationalisierung (nämlich wchar_t + Funktionen darauf) zu verzichten und stattdessen UTF-8 als den Einzig Wahren Weg(TM) anzupreisen. Schließlich habe ich mich rangemacht, und geschaut, welche Funktionen aus wchar.h in NetBSD (die Citrus integriert haben), jedoch nicht in OpenBSD zu finden sind, und bin auf folgendes Ergebnis gestoßen. Dadurch, dass das nicht irgendwelche Pipifax-Funktionen sind, sondern da auch ein konkreter Standard bzw. hinreichend verbreitete Implementierungen dahinterstehen, ist die Liste nach Standards sortiert:
Single Unix Specification, Version 2- fwprintf
- fwscanf
- swprintf
- swscanf
- vfwprintf
- vswprintf
- vwprintf
- wprintf (wird aber in der Manpage von wcstok(3) erwähnt...)
- wscanf
Single Unix Specification, Version 3
Proprietär, aber in NetBSD und glibc zu finden- wcsdup
- wcsncasecmp
- wcscasecmp
Man beachte, dass die allermeisten Funktionen schon in SuSv2 spezifiziert sind und es als solche auch in C99 reingeschafft haben.
Tja, und da war es dann aus bei mir mit der guten Laune. Ist es tatsächlich zuviel verlangt von einem doch vergleichsweise populären Betriebssystem (gemessen an der Open-Source-Community, nicht der Gesamtheit aller Computeruser weltweit), etablierte Standards, die thematisch eigentlich genau in die Projektzielsetzung von OpenBSD fallen, umzusetzen, oder ist OpenBSD neuerdings dazu übergegangen, ein möglichst kastriertes System, das entfernt noch irgendwie an Unix erinnert, zu entwickeln? Es ist ja nicht so, dass die Komplexität der oben genannte Funktionen besonders groß wäre, immerhin gibt es davon ja fertige Implementierungen, die sogar in einer für OpenBSD akzeptablen Lizenz vorliegen (nämlich die Entwicklungen des Citrus-Projekts).
Unter solchen Voraussetzungen, dass nicht einmal 13 Jahre alte Standards aus dem C- und Unix-Umfeld umgesetzt werden, kann ich auf jeden Fall OpenBSD nicht mehr als ernstzunehmendes Unix-artiges Betriebssystem betrachten. Ich zeige kein Verständnis für Extrawürste und bewusst weggelassene Funktionalität. Solange nicht zumindest swprintf() in OpenBSD existiert, ist newsbeuter-Support für OpenBSD gestorben, explizit auch so dokumentiert, und ich kann nur jedem, der ernsthafte Open-Source-Entwicklung betreiben will, von einer angestrebten Kompatibilität mit OpenBSD abraten, weil dafür im Vergleich zu anderen System riesige Kompromisse eingegangen werden müssten.
Monday, November 5. 2007
Weil ich gerade einen herzlich sinnlosen Patch für das newsbeuter-Makefile gekriegt hab, der pkg-config dazu einsetzt, diverse Libraries zu finden, hab ich im Issue Tracker gleich mal ordentlich gerantet. Und eigentlich sollte dieser pkg-config-Rant auch meinen werten Lesern hier nicht vorenthalten werden: Rejected.
(a) Mentioned libraries are installed in system-wide directories by definition.
(b) When a user is capable installing it outside of the usual system-wide directories, he's also capable of adapting the Makefile accordingly.
(c) IMHO, it's very unlikely that somebody installs the library somewhere outside of a system-wide directory, but then takes care that the according .pc files are installed when pkg-config is searching for it.
A great example for the utter failure of pkg-config is how it fails to work with libraries that are installed via Fink on Mac OS X. Fink installs all its software under /sw, which is definitely not one of the "usual" prefixes such as /usr and /usr/local. And of course, the pkg-config that is delivered with Mac OS X fails to find any of the .pc file that are installed under /sw. When using the pkg-config that is delivered with Fink, the .pc files that are installed under /usr aren't found. In theory, pkg-config is great, but in practise, it's absolutely awful and IMHO less reliable than not using any semi-magic auto-detection mechanism.
Additionally, it depends on glib2, and I'm not going to endorse the installation of a plethora of bloated software that is of no direct use to users of newsbeuter.
Friday, November 2. 2007
Gerade hab ich Hudson ausprobiert, es hat sich als wirklich nettes Continuous-Integration-Tool herausgestellt. Primär interessiert bin ich natürlich an Continuous Integration für newsbeuter, gleichzeitig dient diese Evaluierung aber auch küntigen potentiellen anderen Einsätzen.
Das Setup von Hudson ist einfach: das .jar-File von der Website herunterladen, "java -jar hudson.jar" ausführen, und nach kurzer Zeit ist das Hudson-Webinterface schon auf localhost:8080 verfügbar (alternativ ist das Deployment in einem Servlet-Container auch möglich, aber sowas hab und brauch ich nicht). In diesem Webinterface erstellt man dann einen neuen Job, bei dem man angibt, as welchem CVS- oder SVN-Repository der Code ausgecheckt werden soll, wie ein Build getriggert werden soll, welche Kommandos ausgeführt werden sollen (bei nicht-Java-Dingen ist das Ausführen von Shellkommandos am zweckmäßigsten, um Buildtools wie make sowie das Ausführen von Unit-Tests zu steuern), und wie die Email-Notification ablaufen soll. Dann ist der Job schon einsatzbereit, und man kann einen Build starten, um zu testen, ob der Build auch korrekt abläuft.
Abgesehen von der Abhängigkeit von Java ist Hudson wirklich sehr angenehm, und ich kann es voll und ganz weiterempfehlen, vorausgesetzt, man setzt kein exotisches SCM ein (CVS und Subversion werden unterstützt). Auch für künftige Projekte werde ich es sicher einsetzen.
Tuesday, September 11. 2007
Es gibt einen neuen RSS-Feedreader für die Textkonsole, und zwar NRSS. Ich hab mir mal ein wenig Zeit genommen, und ihn mir angeschaut.
Zu Beginn unangenehm fällt auf, dass Import von OPML-Dateien nicht möglich ist. Gut, dann befüllen wir ~/.nrss/config mit ein paar URLs: add "http://blog.fefe.de/rss.xml?html" "Fefe's Blog"
add "http://www.sixapart.jp/business/index.xml" "Unicode-Test"
add "http://diveintomark.org/feed/" "Dive Into Mark (Atom)"
add "http://venzi.wordpress.com/feed/" "Venzis Blog" Ich starte also NRSS, und was passiert? NRSS beginnt sofort, alle Feeds zu reloaden, und crashed bei der URL http://diveintomark.org/feed/. Tja. Atom funktioniert offenbar nicht. Also entferne ich diesen Feed aus der Konfiguration.
Das Interface sieht eher ungewohnt aus, und zwar sieht man einen Feed, direkt darunter alle Artikel des Feeds, dann wieder einen Artikel, darunter wieder alle dazugehörigen Artikel, usw. Besonders übersichtlich ist das nicht. Mit "C" kann man einklappen. Hilfe bekommt man übrigens nicht über "h" oder "?", sondern über die unintuitive Taste "u" (as in "toggle- usage").
Man navigiert mit den Cursortasten bzw. Page-Up/Page-Down herum (letztere Tasten springen zum vorigen bzw. nächsten Feed, das ist noch halbwegs erträglich), mit Leerzeichen zeigt man dann den ausgewählten Artikel an. Hier zeigt sich das nächste Problem: HTML wird nicht gerendert. Die Config-Dokumentation zu NRSS klärt auf, warum: man muss extra einen Filter konfigurieren (also ein externes Programm), welches das HTML rendert. In der Dokumentation findet sich als Beispiel w3m. Aus der Artikelansicht heraus kann mit den Cursortasten zum vorigen bzw. nächsten Artikel navigieren.
Mit Unicode-Zeichen (konkret getestet hab ich nur mit Japanisch) hat NRSS offenbar ebenfalls Probleme. Zwar werden die Zeichen als solche korrekt gerendert, allerdings sind die Vorder- und Hintergrundfarben offenbar fehlerhaft. Gleiches Verhalten trifft man auch bei Umlauten und dem scharfen S an. Anmerkung: da scheint allerdings auch der Debian-Build etwas kaputt zu sein, händisch gebaut tritt das nämlich nicht auf.
Außerdem scheint es, als würde die Breite von Zeichen nicht korrekt beachtet werden, was dazu führt, dass Teile der Rahmen falsch gezeichnet werden. Mit Ctrl-L, der eigentlich allgemeingültigen Taste zum Neuzeichnen des Bildschirms, lässt sich das allerdings nicht korrigieren. Stattdessen hat man "D" zu drücken.
Nach diesen kurzen Experimenten hatte ich eigentlich schon genug von NRSS, und hab noch ein wenig durch die Dokumentation geblättert. Einzig besonders aufgefallen ist mir doch recht flexible Möglichkeit, mit Format-Strings das Aussehen von NRSS zu verändern. Das geht in newsbeuter (noch) nicht so einfach. Ansonsten hat NRSS meiner Einschätzung nach nichts interessantes zu bieten, selbst Snownews und raggle verfügen da um einiges mehr an Funktionalität.
Friday, August 24. 2007
synflood.at ging es in den letzten Tagen nicht unbedingt gut. Das ist jetzt gefixt (Hardwaredefekt), und das Blog kann wieder den regulären Betrieb aufnehmen. Vorgestern hab ich mich übrigens entschlossen, sämtliche Bloggingtätigkeit zu newsbeuter im Newsbeuter Development Blog weiterzuführen.
Wednesday, August 22. 2007
Ich bin derzeit dabei, ein wenig competitive analysis im Bereich RSS-Feedreader durchzuführen (man muss sich ja mit knackigen Ideen für neue newsbeuter-Features versorgen), und bin im Zuge dessen auf die Idee gekommen, Synchronisations-Support mit diversen Online-RSS-Readern umzusetzen. Etliche Online-RSS-Reader implementieren eine mehr oder weniger komplexe API (auf HTTP-Basis), um eine gewisse Synchronisation durchzuführen. Die größeren "Player" in dem Bereich sind Bloglines, NewsGator und Google Reader.
Nun ja, der Bloglines-Support ist schon implementiert (und funktioniert ganz OK, soweit ich nach den ersten Tests sagen kann), Google Reader hat das Problem, keine öffentliche API-Doku zu haben (es gibt lediglich eine reverse-engineerte), und NewsGator... ja, NewsGator. Die haben eine ziemlich komplexe API. Gut, das ist kein Problem, ganz im Gegenteil, damit könnte man nette Sachen machen. Allerdings: mit der Benützung der API verbunden ist das Einverständnis mit diesem langen License Agreement durch den Entwickler, und man braucht einen API Product Key, bei dessen Beantragung angeben muss, ob das Produkt "commercial" oder "non-commercial" ist. Das License Agreement ist ja schon mal toll, wenn ich nicht mit allem einverstanden bin, darf ich die API nicht einmal implementieren, außerdem muss man bei "non-commercial use" überall, wo als Backend die NewsGator API verwenden wird, das NewsGator-Logo anzeigen, und bei "commercial use" ist sowieso ein License Fee fällig. Da ich in meiner Lizenzierung von newsbeuter aber keine Aussagen über die Verwendung mache (ist mir doch egal, ob da jemand mit newsbeuter Geld verdient, ist sowieso eher unwahrscheinlich), sehe ich mich außerstande, mich auf eine bestimmte Verwendungsart festzulegen, und den jeweiligen Bedingungen (Logo bzw. License Fee) kann ich sowieso nicht folgen. Außerdem ist in dem License Agreement eine Art NDA verpackt. Damit sind die Lizenzbedingungen absolut inakzeptabel, weswegen ich auf keinen Fall jemals NewsGator-Support implementieren werde. Sollte jemand noch andere Online-Reader mit öffentlicher API und weniger restriktiven Nutzungsbedingungen kennen, die auch unterstützenswert sein könnten, bitte ich um freundliche Eingaben in den Kommentaren.
Tuesday, August 7. 2007
Bisher sind schon mehrere Leute auf mich zugekommen, sie wollen doch eine Art "Meta-Feed" in newsbeuter, der alle ungelesenen Feeds enthält. Diesem Wunsch bin ich heute nachgekommen, und hab das gleich schön generalisiert, d.h. jeder Benutzer kann sich seine eigenen Meta-Feeds ("query feeds" im newsbeuter-Jargon) definieren, und zwar auf Basis der newsbeuter-internen Filtersprache. Das funktioniert relativ einfach: man füge einfach eine neue Konfigurationszeile in die Datei ~/.newsbeuter/urls ein, welche mit "query:" beginnt, dann den Namen enthält, auf welchen - durch einen Doppelpunkt getrennt - ein Filterausdruck folgt. Startet man nun newsbeuter, so sieht man diesen neuen Eintrag in der Liste der Feeds, mit dem konfigurierten Namen. Öffnet man diesen Feed, so werden alle heruntergeladenen Artikel, auf die der angegebene Filterausdruck zutrifft, in der Artikelübersicht angezeigt. Der "Klassiker", also die öfter geforderte Funktionalität, alle ungelesenen Artikel aller Feeds anzuzeigen, sieht dann in der Konfiguration so aus:
"query:Unread Articles:unread = \"yes\""
Man achte auf das Quoting: da die pseudo-URL Leerzeichen enthält, muss diese als ganze gequoted werden. Da im Filterausdruck ebenfalls Quotes vorkommen, müssen diese passend escaped werden. Ganz praktisch auch das Zusammenfassen von mehreren mit dem selben Tag versehenen Feeds zu einem einzigen Feed:
"query:gesammelte Artikel:tags # \"tagname\""
Im Grunde genommen sind die Möglichkeiten der Query Feeds nur eingeschränkt durch die mit der Filtersprache abfragbaren Attribute und die eigene Kreativität.
Die Query Feeds werden Teil des nächsten Releases sein, das diesmal weniger lang auf sich warten lassen wird als das letzte Release 0.5. Zusätzliche Features werden da u.a. auch das Neuladen des urls-File von newsbeuter aus (Kleinigkeit, aber trotzdem praktisch) und eine Eingabe-History für die Filtereingabefelder und die interne Kommandozeile sein.
Monday, June 4. 2007
Freitag und Samstag war ich auf den Linuxwochen in Wien, und ich muss sagen, das war ein sehr produktives Wochenende. Ich hab selbst einiges an newsbeuter weiterarbeiten können, und Clifford hat auch an der STFL einiges erweitert. So wird jetzt z.B. der Cursor in Listen am Anfang des jeweiligen ausgewählten Eintrag platziert, was inbesondere für Braille-Zeilen relevant ist. Ausserdem können jetzt die Keybindings der Widgets durch eine Belegungen ersetzt oder ergänzt werden (in newsbeuter wird mit diesem Feature die Navigation durch Listen konfigurierbar gemacht), und man kann durch Tastendrücke beliebige Events generieren. Auch ansonsten konnte ich einige Leute von newsbeuter überzeugen, die Userbase wird also noch weiter steigen. Insbesondere die Möglichkeit, etwas direkt herzuzeigen, und sofort auf Fragen eingehen zu können, ist wirklich spannend. Man hat unmittelbares User-Feedback, was als Entwickler äußerst angenehm ist.
Thursday, May 31. 2007
Es tut sich wieder was bei newsbeuter. Und zwar hab ich in den letzten Tagen eine Filtersprache entwickelt, um dynamische Abfragen für theoretisch alles zu ermöglichen, primär aber, um Feeds und Artikel in Feeds zu filtern, nach Kriterien wie Autor, Titel, Inhalt, Veröffentlichungsdatum, Anzahl der ungelesenen Artikel, URL des RSS-Feeds, usw. usf. Derzeit ist es so implementiert, dass man in der Feedübersicht die Taste F drückt, eine Abfrage eingibt, die gefilterte Feedübersicht präsentiert kriegt, und diese Filterung wieder löschen kann. Ein Abfrage sieht etwa so aus: unread_count > 0 and unread_count <= 20 Mit dieser Abfrage erhält man alle Feeds, die mindestens einen, aber 20 oder weniger ungelesene Artikel enthalten. Bald werden auch solche Abfragen möglich sein: ( author =~ "Frank" or author =~ "John" ) and ( title =~ "Linux" or title =~ "FreeBSD" ) Das würde alle Artikel der Autoren "Frank" oder "John" (als Text innerhalb der Quotes sind übrigens Regular Expressions möglich) mit "Linux" oder "FreeBSD" im Titel. Eine freie Gestaltung der Abfragen ist möglich, "the sky is the limit" wie es im Englischen so schön heisst. Die Abfrage rssurl =~ "^https:" filtert übrigens alle Feeds mit HTTPS-URL heraus. Wie man merkt, kommt man mit diesen Mitteln schnell zu vorher ungeahnten Möglichkeiten.
Implementiert habe ich den Parser für diese Abfragesprache übrigens mit Coco/R für C++, ein Compilergenerator, der an der Uni Linz entwickelt wird. Das ging ziemlich schnell und intuitiv, und mit den verfügbaren Beispielen für z.B. dem Compiler für die Minisprache Taste war es auch mir Compilerbau-Unerfahrenen möglich, schnell zu einem funktionierenden Parser zu gelangen. Die Code-Templates für die Generierung der Klassen rundherum (die "frame files") musste ich etwas adaptieren, etwa um aus einem std::istream statt aus einem FILE* zu parsen (was den Vorteil hat, über std::ifstream Dateien und über std::istringstream auch Strings anbinden zu können). Die Anbindung an newsbeuter selbst habe ich so gestaltet, dass ich einen Matcher implementiert habe, der einen geparsten Ausdruck gegen jedes beliebige Objekt prüfen kann, solange dieses nur von der Basisklasse matchable (enthält lediglich zwei pure virtual functions zum überprüfen, ob ein Attribut vorhanden ist, bzw. um dessen Wert abzurufen) abgeleitet ist. Damit erhalte ich die größtmögliche Flexibilität, und kann eben theoretisch jedes Objekt matchen (auch wenn das nicht wirklich bei allen Objekten innerhalb von newsbeuter Sinn macht). Die eigentliche Integration war mit diesen Vorarbeiten dann ein Kinderspiel, und mittlerweile ist die Funktion zum Verstecken der bereits gelesenen Feeds sogar über die Filtersprache implementiert (über exakt den gleichen Mechanismus hängen sich dann auch die anderen Filterabfragen rein). Erstmals präsentieren werde ich dieses neue Feature übrigens übermorgen auf den Linuxwochen Wien. Kommt zahlreich.
Friday, May 18. 2007
So, heute geht's nach Graz, wo morgen die Linuxtage stattfinden. Ich bin mit meinem Vortrag über newsbeuter dabei (schöne Grüße an den Herrn PR, der den Namen jedesmal spöttisch ausspricht, wenn ich ihn erwähne, und der sich längstens eine Windows-GUI-Version davon wünscht). Nun denn, ich hab spontan entschlossen, aufgrund der schlechten Zugverbindung schon um 11:10 loszufahren, damit ich um 14:00 in Graz ankomme. An meinen Slides muss ich noch etwas feilen, da werd ich eh noch genug Zeit haben dafür. Na dann...
Tuesday, May 8. 2007
newsbeuter 0.4 ist released. Die Konfigurationsmöglichkeiten haben sich verbessert, die Geschwindigkeit des Reload hat sich massiv verbessert, es gibt Unit Tests und eine italienische Übersetzung, und, was das tollste ist, newsbeuter unterstützt jetzt auch Snownews/Liferea extensions. Damit gibt es keinen Grund mehr, nicht von snownews auf newsbeuter umzusteigen.
Tuesday, May 1. 2007
 So, es ist offiziell: meine eingerichten Vorträge zu newsbeuter wurden sowohl auf den Grazer Linuxtagen als auch auf den Linuxwochen Wien genommen. Es erwartet jeden Besucher eine Einführung in newsbeuter, eine Feature Show, die zeigt, wie mächtig newsbeuter wirklich ist, und dann noch ein Blick "hinter die Kulissen", wie newsbeuter intern funktioniert, und welche Lehren ich aus der bisherigen Entwicklung gezogen habe. In spätestens einer Woche wird übrigens die Version 0.4 released werden, die einige tolle neue Features am Start hat.
Monday, April 2. 2007
Ein paar Alternativen zum derzeitigen make-basierten Buildsystem bei newsbeuter evaluiert. SCons und CMake. Frustriert wieder aufgegeben, weil sich die Anforderungen, die ich habe, entweder mit viel Fummelei oder gleich gar nicht umsetzbar sind. Mit SCons hab ich durch etwas umstrukturieren (gemeinsam genutzte Objekte musste ich in eine statische Lib zusammenfassen, sonst will SCons da garnichts compilieren) den Buildprozess so hingebracht, wie ich wollte, und CMake... naja, sagen wir mal so, man merkt an der Qualitaet der CMake-Dokumentation, dass es auch ein CMake-Buch gibt.
Was sind überhaupt meine Anforderungen? Es sollen zwei Binaries erzeugt werden, aus C++-Sourcecode, wobei sich beide Binaries eine gewisse Anzahl von C++-Sourcefiles teilen. Zusaetzlich gibt es noch regulaere Header-Files sowie .stfl-Files, die durch ein Perl-Preprocessor-Script in Header-Files umgewandelt werden. Die Umsetzung als Makefile ist halbwegs kompakt, und noch gut wartbar.
Wie schon oben beschrieben, der vielversprechendste Kandidat schien SCons zu sein, bis ich mir dann genauer angeschaut habe, wie man die Installation von Dateien umsetzen soll. Das ist, mit Verlaub, der hirnrissigste Schwachsinn, den ich jemals gesehen habe. Die SCons-Leute haben eindeutig die falschen Drogen konsumiert, wie sie das designed haben. Nein, das will ich nicht benutzen.
Warum tu ich mir das ueberhaupt an? Weil ich vor dem eigentlichen Compile auch ein paar Details ueber die Zielplattform rausfinden will (und zwar mehr als nur triviales "ist Header foobar.h vorhanden" und "ist Library libquux eh da"), und mit reinen Makefiles ist das ein einziger PITA. Tja, mit autoconf waeren meine Anforderungen hinreichend gut umsetzbar, weil das Makefile ohne viel Aufwand portierbar waere, aber das will ich mir selbst nicht antun. autoconf ist zwar gut customizable, aber ein einziger Haufen Dreck, vor allem weil es dann zu Zustaenden wie den folgenden fuehren wuerde:
-rwxr-xr-x 1 ak ak 43K 2007-04-02 13:03 config.guess
-rwxr-xr-x 1 ak ak 15K 2007-04-02 13:03 config.rpath
-rwxr-xr-x 1 ak ak 28K 2007-04-02 13:06 config.status
-rwxr-xr-x 1 ak ak 31K 2007-04-02 13:02 config.sub
-rwxr-xr-x 1 ak ak 156K 2007-04-02 13:05 configure
-rwxr-xr-x 1 ak ak 9.1K 2007-04-02 12:43 install-sh
Ja, richtig gesehen, das sind knapp 280 kB Skripte, die da zusaetzlich mitgeshipped werden wuerden, fuer ein paar simple Tests.
Und eines kann ich auch ausschließen: ich werde sicher kein zusaetzliches Build-Tool entwickeln, das kann nur in die Hose gehen. Tja, alles scheisse eben.
Friday, March 9. 2007
Heute hab ich wieder einiges an Arbeit investiert, um newsbeuter (besser) zu internationalisieren. Und das ist dabei herausgekommen:
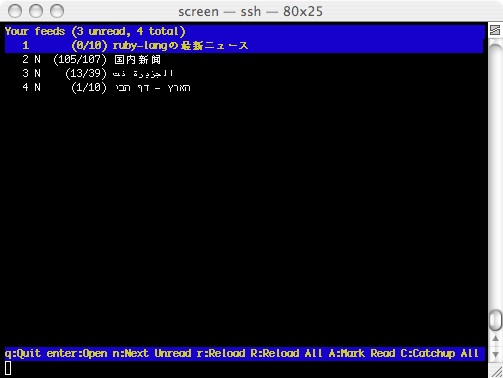
Von oben nach unten: Japanisch, Chinesisch, Arabisch und Hebräisch.
Thursday, February 22. 2007
Eines der Features, das newsbeuter 0.3 haben wird, ist eine sprachliche Lokalisierung. gettext-Support ist schon im SVN-Head, was jetzt noch fehlt, sind passende Übersetzungen. Die einzigen natürlichen Sprachen, die ich spreche, sind Deutsch und Englisch, und dementsprechend gibt es gerade mal eine Übersetzung, nämlich die ins Deutsche.
Deswegen hier der Aufruf: wenn irgendjemand noch eine andere Sprache als die beiden oben genannten spricht, und newsbeuter übersetzen will, wäre ich sehr dankbar. Derzeit sind es gerade mal knapp über 90 Zeichenketten, die zu übersetzen wären, also kein zu großer Aufwand. Das Template für die Übersetzung findet sich hier, als Beispiel, wie das resultierende File nach der Übersetzung aussieht, kann man sich das bereits existierende de.po anschauen. Für jegliche Einsendungen an ak-newsbeuter@synflood.at bin ich herzlich dankbar.
|