Entries tagged as programming
army debugging dog tag fun hacking x86 23c3 beer berlin bullshit c c++ christmas clouds darklab discordianism feedreader fefe flight fnord html hype jeopardy lawblog lectures linz network noos photos programme rant rss security server terrorism texttools trapdoor2 travelling unix vienna ada ariane 5 burning money announcement baconbird debian features newsbeuter perl release software stfl twitter 1 22c3 accident austria austrofascism complaint end german guard hair iraq israel kidnapping mercenary movie police propaganda recommendation shooting soldier tv unemployment usa war wikipedia work youtube assembler gcc recursion automated tests ncurses terminal testing gockel golang borland google japanese job mobile silkperformer translation wap web webdynamite build management continuous integration cruisecontrol hudson contrapolice designbycontract dietlibc git heap history introduction ndbm overflow performance strdup cms compiler http javascript parser problem refactoring ruby stack weird xml callgraph dot shared library idea code audit gnupg code coverage gcov lcov community rails console tpp cvs java subversion dartlang websockets 2 editor ide vim email docbook documentation imap mutt mutt-ng patch management prototype quilt screencast smtp swig synflood thread embeddable object-oriented python scripting language archive bsd censorship gpl license mit news forced browsing free pascal gnu pascal neted pascal freebsd glibc i18n icu linux netbsd plan9 unicode 3 3d 9/11 accesslog acm alcohol animation apache arc arselectronica aspirin avantgarde bear benchmark bka blog blogging book cabaret cats chocolate christianity cocaine commands commercials computer science conspiracy cooking cover versions crossroads cwapd doping drugs eastgermany eiffel electronic music english essay fail first! flash food fuzz gangsigns gatling grammar gunkl heroin horror hymn icq independence indymedia internet it jan ullrich jmeter kaminer letter lisp lolcats mathematics meme money music nerds passiveaggressivenote picture pictures pixar pizza podcast polenta politics pope present programming language prototyping quiz quotes religion russendisko sangria sex shell skabucks socialism swebd techno thttpd tooth upperaustria vcs vegetables video weekend whale whip whitechicks windows wplotd air antigen aphex twin art björk bmw bushgohome callofduty2 chris cunningham demo environment eu filter games gas mask going out humanrights liwest microsoft nato nissan notwehr particulate matter pearl jam rootserver sleep torture traffic uno C djb make redo citrus openbsd go flight simulator google chrome google earth himalaya privacy 4 cnn new york washington eruby html generation static content wml wsg 1337 h4x0r banner grabbing ddos digg dos fingerprinting proxy slowloris ssh improvements liam maildir mbox mime ipv6 relocation autoconf automake event gnu graz iconv lecture linuxtage metalab solaris wien linuxwochen blue sky brutality concert google maps hugin panorama posthof pöstlingberg rap reggae repression ska thesmilingsunriseband tocotronic view violence hack infrared k610i nightvision bashing cmake hardware l10n newsgator nrss opml pkg-config scons name trademark obscure osx pthread shower argentina football fundamentalism germany headache movies one referee schwarzer southpark stallman toilet pop3 cygwin error face funny image sqlite tcl 5
Tuesday, November 21. 2006
noos, ein RSS-Feedreader für die Konsole
In den letzten 2 Wochenenden hab ich an einem neuen Tool gebastelt, und zwar an noos, einem RSS-Feedreader für die Konsole. Zwar gibt es sowas schon, wie etwa snownews und raggle. Mit beiden Readern war ich aber nicht sehr zufrieden, snownews etwa wirkte auf mich immer etwas krude und das Interface etwas plump zusammengehackt, und raggle verhielt sich immer äußerst behäbig. Also hab ich mich mal rangesetzt, und was eigenes geschrieben. Und somit kann die Version 0.1 von noos präsentieren, die allerdings noch eher ein pre-alpha-Version ist, mit lediglich den rudimentärsten Features.
noos 0.1 hier runterladen
Die Abhängigkeiten sind etwas umfangreicher. Als UI-Toolkit habe ich STFL verwendet, da ich damit schon ein paar Prototypen und halbfertige Projekte realisiert habe. Zum Downloaden und Parsen der RSS-Feeds hab ich auf libmRss zurückgegriffen, welche wiederum abhängig ist von libnxml, die ich für den OPML-Import verwendet habe. Und als Storage-Backend für den Item-Cache hab ich mich für das bewährte SQLite entschieden. Zwei Wochenende und 1000 Zeilen C++ später steht also eine erste verwendbare Version. Die Features sind noch etwas dürftig, und das Rendering des HTML in den Descriptions ist noch total zum vergessen, aber es ist schon ein guter Ansatz sichtbar.
Und hier noch ein Screenshot:
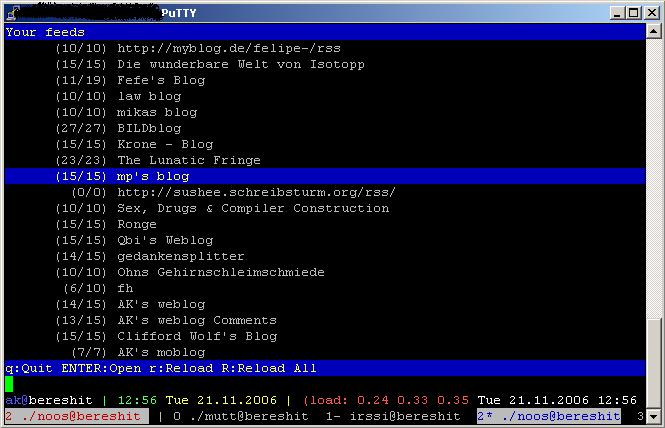
Feedback welcome.
noos 0.1 hier runterladen
Die Abhängigkeiten sind etwas umfangreicher. Als UI-Toolkit habe ich STFL verwendet, da ich damit schon ein paar Prototypen und halbfertige Projekte realisiert habe. Zum Downloaden und Parsen der RSS-Feeds hab ich auf libmRss zurückgegriffen, welche wiederum abhängig ist von libnxml, die ich für den OPML-Import verwendet habe. Und als Storage-Backend für den Item-Cache hab ich mich für das bewährte SQLite entschieden. Zwei Wochenende und 1000 Zeilen C++ später steht also eine erste verwendbare Version. Die Features sind noch etwas dürftig, und das Rendering des HTML in den Descriptions ist noch total zum vergessen, aber es ist schon ein guter Ansatz sichtbar.
Und hier noch ein Screenshot:
Feedback welcome.
Thursday, November 9. 2006
A "long long long" time ago...
Wednesday, November 1. 2006
gdb-Breakpoints detecten
Durch ein sehr simples Demo-Programm aus dem lokalen IRC-Channel bin ich inspiriert worden, das ganze etwas zu verbessern, und ein paar simple Funktionen zu schreiben, mit denen man zur Laufzeit erkennen kann, ob innerhalb eines bestimmten Code ein Breakpoint gesetzt worden ist. Den Code dazu gibt's hier zum anschauen, und hier eine kurze Session:
$ gcc -g antibreak.c -o antibreak
$ ./antibreak
i=0
i=1
i=2
$ gdb antibreak
GNU gdb 6.3-debian
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-linux"...Using host libthread_db library "/lib/tls/libthread_db.so.1".
(gdb) break antibreak.c:11
Breakpoint 1 at 0x8048408: file antibreak.c, line 11.
(gdb) break antibreak.c:19
Breakpoint 2 at 0x804843d: file antibreak.c, line 19.
(gdb) break antibreak.c:32
Breakpoint 3 at 0x80484ce: file antibreak.c, line 32.
(gdb) r
Starting program: /home/ak/antibreak/antibreak
found breakpoint at address 0x0x8048408
found breakpoint at address 0x0x804843d
found breakpoint at address 0x0x80484ce
Program exited with code 01.
(gdb) quit
$
Um das gleich mal am anfang zu klären: ja, das funktioniert auch ohne -g, allerdings kann man dann im gdb keine Breakpoints auf Zeilennummern setzen.
Der Hintergrund: gdb setzt Breakpoints, indem der Maschinencode im Speicher so verändert wird, dass an der jeweiligen Stelle ein INT 3 (Opcode 0xCC) reingeschrieben wird.. Wird diese Stelle nun ausgeführt, löst dieser INT 3 einen Trap aus, bei dem sich gdb reinhängt, und vor einem Continue an die Stelle noch den vorherigen Opcode reinschreibt.
Die von mir geschriebenen Funktionen machen es nun so, dass man eine Start- und eine Endadresse angibt, und dieser Bereich von einem simplen x86 Opcode Decoder angeschaut wird, und wenn ein INT 3 gefunden wird, wird die Adresse der Instruktion zurrückgeliefert. Von diesem Punkt weg kann man dann solange weitere INT-3-Instruktionen suchen, bis man die Endadresse erreicht hatt. Den Opcode Decoder hab ich übrigens nicht selbstgeschrieben, sondern über Google gefunden, und für kompakt genug befunden, um den schnell mal via copy/paste zu verwenden. Als End-Adresse hab ich übrigens in allen Fällen die Startadresse der nächsten Funktion im Sourceode verwendet. Klar, das verlässt sich auf ein gcc-spezifisches Verhalten, aber hey, das ganze ist sowieso auch x86-spezifisch, also, was soll's?
Wer übrigens noch mehr über ein paar nette Anti-Debugging-Techniken unter Linux lesen möchste (kein Voodoo-Techniken, aber trotzdem ganz interessant für n00bs wie mich), dem kann ich nur diesen Text empfehlen.
Wie ich übrigens aus gut informierten Kreisen erfahren habe, gibt es noch eine andere Debugging-Technik, die auf den Debug-Registern des x86 aufbauen, und das dürfte von neueren gdb-Versionen schon (teilweise) unterstützt werden. Insofern ist nicht garantiert, dass das in Zukunft auch nur irgendwie funktioniert.
$ gcc -g antibreak.c -o antibreak
$ ./antibreak
i=0
i=1
i=2
$ gdb antibreak
GNU gdb 6.3-debian
Copyright 2004 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i386-linux"...Using host libthread_db library "/lib/tls/libthread_db.so.1".
(gdb) break antibreak.c:11
Breakpoint 1 at 0x8048408: file antibreak.c, line 11.
(gdb) break antibreak.c:19
Breakpoint 2 at 0x804843d: file antibreak.c, line 19.
(gdb) break antibreak.c:32
Breakpoint 3 at 0x80484ce: file antibreak.c, line 32.
(gdb) r
Starting program: /home/ak/antibreak/antibreak
found breakpoint at address 0x0x8048408
found breakpoint at address 0x0x804843d
found breakpoint at address 0x0x80484ce
Program exited with code 01.
(gdb) quit
$
Um das gleich mal am anfang zu klären: ja, das funktioniert auch ohne -g, allerdings kann man dann im gdb keine Breakpoints auf Zeilennummern setzen.
Der Hintergrund: gdb setzt Breakpoints, indem der Maschinencode im Speicher so verändert wird, dass an der jeweiligen Stelle ein INT 3 (Opcode 0xCC) reingeschrieben wird.. Wird diese Stelle nun ausgeführt, löst dieser INT 3 einen Trap aus, bei dem sich gdb reinhängt, und vor einem Continue an die Stelle noch den vorherigen Opcode reinschreibt.
Die von mir geschriebenen Funktionen machen es nun so, dass man eine Start- und eine Endadresse angibt, und dieser Bereich von einem simplen x86 Opcode Decoder angeschaut wird, und wenn ein INT 3 gefunden wird, wird die Adresse der Instruktion zurrückgeliefert. Von diesem Punkt weg kann man dann solange weitere INT-3-Instruktionen suchen, bis man die Endadresse erreicht hatt. Den Opcode Decoder hab ich übrigens nicht selbstgeschrieben, sondern über Google gefunden, und für kompakt genug befunden, um den schnell mal via copy/paste zu verwenden. Als End-Adresse hab ich übrigens in allen Fällen die Startadresse der nächsten Funktion im Sourceode verwendet. Klar, das verlässt sich auf ein gcc-spezifisches Verhalten, aber hey, das ganze ist sowieso auch x86-spezifisch, also, was soll's?
Wer übrigens noch mehr über ein paar nette Anti-Debugging-Techniken unter Linux lesen möchste (kein Voodoo-Techniken, aber trotzdem ganz interessant für n00bs wie mich), dem kann ich nur diesen Text empfehlen.
Wie ich übrigens aus gut informierten Kreisen erfahren habe, gibt es noch eine andere Debugging-Technik, die auf den Debug-Registern des x86 aufbauen, und das dürfte von neueren gdb-Versionen schon (teilweise) unterstützt werden. Insofern ist nicht garantiert, dass das in Zukunft auch nur irgendwie funktioniert.
Sunday, October 22. 2006
mutt-ng, 2. Versuch
Saturday, October 21. 2006
w3bfukk0r 0.2
Friday, October 6. 2006
Die erste Arbeitswoche
Monday, October 2. 2006
Der erste Arbeitstag
Saturday, September 16. 2006
w3bfukk0r, ein Forced Browsing Tool
Saturday, September 2. 2006
Neue Herausforderungen
Saturday, August 12. 2006
My submission to 23C3
Thursday, August 10. 2006
NDBM implementation for dietlibc
Tuesday, July 25. 2006
liam progress
Sunday, July 23. 2006
Prototyping an IMAP mail client
Friday, June 30. 2006
Reworking the tpp file format
Sunday, June 25. 2006
HTTP stack/server now multithreaded
Today I finally sat down to remodel my HTTP stack/server from a forking model to a multithreaded model using the pthread library. Actually, this is my first project where I use POSIX threads, and I was delighted how easy it was to integrate them into my relatively well-designed program.
The server now works as follows: the "main" thread first creates a number of worker threads, and then accepts connections, puts them into a queue and then notifies the worker threads. The next worker thread that is ready takes the connection from the queue and handles the incoming requests. This is definitely a very simple design, which was also very easy to implement. The results can be found in httpstack/branches/pthread in the SVN repository. As usual, comments are welcome.
The next thing is where I will move that project. One idea I had was to integrate a database connection pool, and in addition probably a simple object-relational mapper, then an HTTP management interface for the whole thing and then some CMS.
The server now works as follows: the "main" thread first creates a number of worker threads, and then accepts connections, puts them into a queue and then notifies the worker threads. The next worker thread that is ready takes the connection from the queue and handles the incoming requests. This is definitely a very simple design, which was also very easy to implement. The results can be found in httpstack/branches/pthread in the SVN repository. As usual, comments are welcome.
The next thing is where I will move that project. One idea I had was to integrate a database connection pool, and in addition probably a simple object-relational mapper, then an HTTP management interface for the whole thing and then some CMS.
About Me

Andreas Krennmair, software engineer, open-source developer, currently living and working in Berlin, Germany.
Calendar
|
|
July '17 | |||||
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 | ||||||
Quicksearch
Show tagged entries
22c3 23c3 amsterdam announcement apache argentina army austria beer berlin book borland bsd c c++ camera censorship christianity cms complaint concert cooking egypt electronic music email fail feedreader fefe food fun gas mask gcc german germany git gnu golang google google earth hacking history html http i18n imap internet israel job kaminer lecture linux linz mobile movie music network newsbeuter noos panorama pearl jam performance photo photography photos pictures polaroid police politics problem programming python quiz rant recommendation release rss ruby screencast seagull security series server ska skabucks stfl terrorism travelling tv unix usa video videos vienna war weird wikipedia windows work wplotd youtube
Buttons









Syndicate This Blog

Blog Administration
Powered by



Blogroll
• xkcd.com
• Planet Debian
• MY POV ([expect the unexpected])
• C skills
• Planet Erlang / Published News
• armstrong on software
• Photos from akrennmair
• Das Metalab informiert
• dive into mark
• /usr/local/bin
• F!XMBR
• heise online News (full feed)
• JLog
• SecuriTeam Blogs
• .:Computer Defense:.
• Riot Porn
• Chaosradio
• Radiomultikulti vom RBB: Russendisko unplugged
• AK's weblog
• The Recurity Lablog
• milw0rm.com
• seclog.de
• ilja's blag
• udo.kernecker.at - mein leben als prinzregent... ;-)
• grabnerandi.at diary feed
• Hilli's WebLog
• accidents waiting to happen
• Venzi's Weblog
• TaoSecurity
• Irrlicht3d.org
• murphee's Rant
• waiterrant.net
• grml development blog
• mutt Changelog
• nion's blog
• Wannabe Everything
• blog@bytelabs
• Knowledge Brings Fear
• Die wunderbare Welt von Isotopp
• Fefes Blog
• law blog
• mikas blog
• BILDblog
• GoogleWatchBlog
• Krone - Blog
• The Lunatic Fringe
• mp's blog
• Su-Shee 2.0
• Sex, Drugs & Compiler Construction
• Qbi's Weblog
• gedankensplitter
• Ohns Gehirnschleimschmiede
• fh
• Clifford Wolf's Blog
• AK's moblog
• Telepolis News
• Slashdot
• Newssystem von bundesheer.at
• Riding Rails - home
• Serendipity
• O'Reilly Ruby
• CCC Events Weblog
• del.icio.us/dubrider
• del.icio.us/timpritlove
• del.icio.us/ak
• del.icio.us/mika
• AK's Soup
• Friends of ak
• Astronomy Picture of the Day
• german-bash.org - Die neuesten Zitate
• QDB
• WeirdWeirdWorld Latest Feed
• I CAN HAS CHEEZBURGER?
• The Trailer Mash
• Cruel.Com
• fun.drno.de
• Peter Pilz grüner Sicherheitssprecher Österreich Wien
• NPD-BLOG.INFO
• INSM Watchblog
• Hitler-Blog
• Everybody loves Eric Raymond
• Dilbert
• Planet Debian
• MY POV ([expect the unexpected])
• C skills
• Planet Erlang / Published News
• armstrong on software
• Photos from akrennmair
• Das Metalab informiert
• dive into mark
• /usr/local/bin
• F!XMBR
• heise online News (full feed)
• JLog
• SecuriTeam Blogs
• .:Computer Defense:.
• Riot Porn
• Chaosradio
• Radiomultikulti vom RBB: Russendisko unplugged
• AK's weblog
• The Recurity Lablog
• milw0rm.com
• seclog.de
• ilja's blag
• udo.kernecker.at - mein leben als prinzregent... ;-)
• grabnerandi.at diary feed
• Hilli's WebLog
• accidents waiting to happen
• Venzi's Weblog
• TaoSecurity
• Irrlicht3d.org
• murphee's Rant
• waiterrant.net
• grml development blog
• mutt Changelog
• nion's blog
• Wannabe Everything
• blog@bytelabs
• Knowledge Brings Fear
• Die wunderbare Welt von Isotopp
• Fefes Blog
• law blog
• mikas blog
• BILDblog
• GoogleWatchBlog
• Krone - Blog
• The Lunatic Fringe
• mp's blog
• Su-Shee 2.0
• Sex, Drugs & Compiler Construction
• Qbi's Weblog
• gedankensplitter
• Ohns Gehirnschleimschmiede
• fh
• Clifford Wolf's Blog
• AK's moblog
• Telepolis News
• Slashdot
• Newssystem von bundesheer.at
• Riding Rails - home
• Serendipity
• O'Reilly Ruby
• CCC Events Weblog
• del.icio.us/dubrider
• del.icio.us/timpritlove
• del.icio.us/ak
• del.icio.us/mika
• AK's Soup
• Friends of ak
• Astronomy Picture of the Day
• german-bash.org - Die neuesten Zitate
• QDB
• WeirdWeirdWorld Latest Feed
• I CAN HAS CHEEZBURGER?
• The Trailer Mash
• Cruel.Com
• fun.drno.de
• Peter Pilz grüner Sicherheitssprecher Österreich Wien
• NPD-BLOG.INFO
• INSM Watchblog
• Hitler-Blog
• Everybody loves Eric Raymond
• Dilbert